


Báječný svět počítačových sítí
Část XI: Síťová vrstva a směrování
Vrstva síťová, která je třetí vrstvou referenčního modelu ISO/OSI (počítáno odspodu), má za úkol dopravovat data přes mezilehlé uzly tak, aby se dostala až ke svým konečným příjemcům. Aby síťová vrstva něco takového dokázala, musí být schopna vyhledávat vhodné cesty v síti či v celé soustavě vzájemně propojených sítí. Tomu se říká směrování, anglicky routing. Zařízení, které směrování zajišťuje, se označuje jako směrovač, anglicky router.V našem putování báječným světem počítačových sítí jsme již prošli dvěma nejnižšími vrstvami referenčního modelu ISO/OSI - nejprve nejspodnější vrstvou fyzickou, a pak druhou nejnižší vrstvou linkovou. Přitom jsme si řekli, že vrstva fyzická má za úkol přenášet jednotlivé bity mezi sousedními uzly, ale nijak je přitom "neskládá dohromady", resp. nezajímá se o to, zda více jednotlivých bitů tvoří nějaký souvislý blok. To zajímá až bezprostředně vyšší vrstvu linkovou, která využívá přenosových služeb fyzické vrstvy (charakteru "přenes bit"), a s jejich pomocí již přenáší celé bloky dat, kterým se na úrovni linkové vrstvy říká "rámce" (anglicky: frames).
Linková vrstva ovšem stále ještě přenáší své rámce jen mezi sousedními uzly, neboli mezi takovými, které mají mezi sebou přímé spojení. Lze si to představit také tak, že pro vrstvu linkovou je viditelné pouze její bezprostřední okolí (tvořené sousedními uzly), zatímco o dalších (vzdálenějších) uzlech už nemá žádné povědomí.
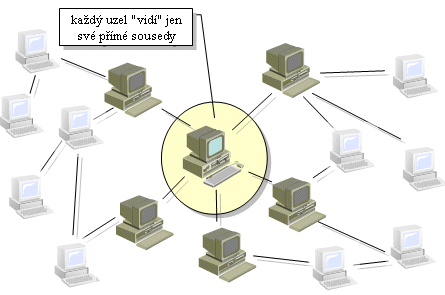 |
Pokud je ale třeba přenést nějaká data právě k těmto vzdálenějším uzlům, které již jsou mimo "záběr" linkové vrstvy (z pohledu odesílajícího uzlu), pak to linková vrstva neřeší. Místo ní už nastupuje vrstva síťová, která již "dohlédne dále" - která zná topologii celé sítě, či celé soustavy vzájemně propojených sítí, a díky tomu dokáže hledat a nacházet cesty ke kterémukoli cílovému uzlu.
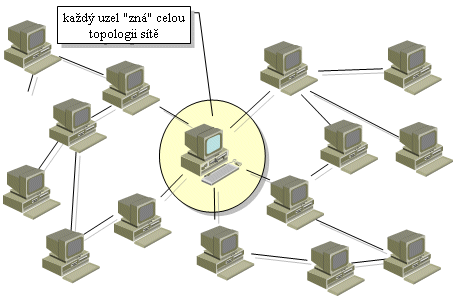 |
Co je směrování?
Samotnému hledání cesty ke koncovému příjemci, které síťová vrstva zajišťuje, se říká směrování (anglicky routing). Jde tedy spíše o logickou ("rozhodovací") funkci, jejímž výsledkem je rozhodnutí o konkrétní cestě pro přenos. Jak záhy uvidíme, postup tohoto rozhodování může být založen na opravdu různých principech., přístupech i metodách. Podle toho se pak také hovoří například o centralizovaném směrování, izolovaném či distribuovaném směrování, či směrování hierarchickém atd.
Samotné rozhodnutí o volbě cesty, a s ním i o směru dalšího přenosu (z pohledu každého uzlu "po cestě"), je ale třeba také konkrétně naplnit. Tedy vzít příslušný blok dat (paket, jak se mu říká na úrovni síťové vrstvy), a přenést jej k dalšímu "přestupnímu" uzlu, případné již k samotnému cílovému adresátovi (pokud jde již o konec celé přenosové cesty). Tomu se obvykle říká "forwarding" (v doslovném překladu jakési "předání dál").
Síťová vrstva ovšem sama o sobě nic nepřenáší. To je pouze iluze, vytvořená vrstevnatým charakterem dnešních sítí. Ve skutečnosti totiž síťová vrstva předá svůj paket k přenosu bezprostředně nižší vrstvě, tj. vrstvě linkové. Ta vloží síťový paket do svého rámce (linkového rámce), a ten pak přenáší. Ovšem ani ona jej ve skutečnosti sama nepřenáší, nýbrž nechává si jeho jednotlivé bity přenést od vrstvy fyzické. Celé to ilustruje následující obrázek.
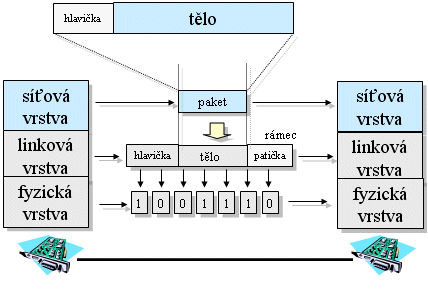 |
Přímé a nepřímé směrování, směrovač
Jak jsme si již řekli, linková vrstva, které vrstva síťová předává své pakety k přenesení, "dohlédne" jen ke svým bezprostředním sousedům, se kterými má přímé spojení (viz výše). V praxi jsou těmito sousedy všechny uzly, které se nachází ve stejné síti. Pokud se tedy přenáší nějaký síťový paket mezi dvěma uzly v rámci stejné sítě, pak má samotná síťová vrstva značně usnadněnou práci, protože nemusí hledat žádné mezilehlé (resp. přestupní) uzly, přes které by měl paket přejít. Takový paket proto síťová vrstva pouze předá linkové vrstvě, která již je schopna jej doručit cílovému adresátovi (neboť ten je v jejím přímém dosahu). Z pohledu síťové vrstvy se tomu říká "přímé směrování", a zde skutečně má síťová vrstva minimum práce a žádné "přemýšlení".
Složitější je to ale v případě, kdy se koncový příjemce nenachází ve stejné síti, jako právě odesílající uzel. Zde již musí síťová vrstva začít hledat vhodnou cestu ke koncovému příjemci, vedoucí přes jeden nebo několik přestupních uzlů. V užším slova smyslu tedy pouze zde, při tzv. nepřímém směrování, provádí síťová vrstva rozhodování, které jsme si výše označili jako samotné směrování (routing).
 |
To, co síťová vrstva při nepřímém směrování hledá, je uzel, vedoucí z dané sítě "ven", do jiné sítě. Tedy jakýsi "přestupní" uzel, resp. "propojovací" uzel (uzel, který vzájemně propojuje dvě různé sítě, či dokonce více takovýchto sítí). Takovémuto uzlu se říká směrovač (router), a v každé síti, která není zcela izolována od svého okolí, je nejméně jeden. Odpovídá to tzv. katenetovému modelu, v rámci kterého jsou jednotlivé sítě propojeny, pomocí směrovačů, do celé soustavy vzájemně propojených sítí. Na takovémto katenetovém modelu je vybudován například dnešní Internet, ale obecně z něj vychází prakticky všechny počítačové sítě.
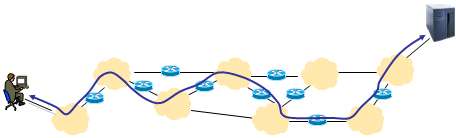 |
Takže každý uzel dané sítě, který chce přenést nějaký svůj paket do jiné sítě (tj. v rámci nepřímého směrování), musí najít vhodný směrovač, vedoucí "z jeho sítě ven". Tomu pak svůj paket "předá dál".
Celý proces postupného předávání se přitom opakuje tak dlouho, dokud se paket nedostane ke svému cíli. I každý směrovač, přes který paket na své cestě prochází, se vždy musí nejprve rozhodnout, zda už je konečný příjemce v jeho přímém dosahu či nikoli. Pokud ano, dochází k přímému směrování (paket je předán linkové vrstvě k přímému doručení koncovému příjemci). Pokud konečný příjemce ještě není v přímém dosahu (tj. nenachází se v žádné síti, do které je směrovač zapojen), pak dochází znovu k nepřímému směrování - směrovač hledá další směrovač (vedoucí do dalších sítí), kterému by paket předal k doručení. Výsledkem je pak cesta, tvořená posloupností takovýchto směrovačů. Přes ně paket postupně prochází, než se dostane ke svému koncovému příjemci. Situaci ilustruje následující obrázek.
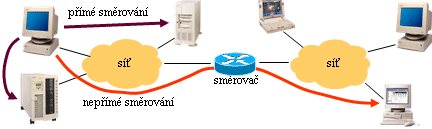 |
Kdo směruje?
Pro dokreslení celé představy o fungování síťové vrstvy se ještě zastavme u toho, kdo vlastně provádí směrování, coby logické rozhodování o směru přenosu. Činí tak hlavně směrovače, ale nejen ony. Směrování se obecně účastní i ostatní uzly (koncové uzly), pokud něco odesílají - protože i ony si musí umět vybrat mezi (potenciálně) více směrovači, které vedou "ven" z příslušné sítě. Odesílající uzel se také nejprve rozhoduje mezi přímým a nepřímým směrováním, a v případě nepřímého směrování vybírá vhodný směrovač. Takže i on by měl mít dostatečné informace na to, aby si při nepřímém směrování dokázal vhodně vybrat.
Například v rodině protokolů TCP/IP, resp. v sítích s těmito protokoly (tedy například v Internetu) je to tak, že každý koncový uzel (například každý osobní počítač atd.) by měl "od narození" znát alespoň jeden směrovač, vedoucí z jeho sítě ven. Pravda, existují sice postupy, které by mu umožnily začít fungovat i bez této znalosti a adresu směrovače si zjistit - ale v praxi se dává přednost tomu, aby každý uzel dostal dopředu (v rámci své konfigurace) potřebnou informaci o alespoň jednom takovém směrovači. Zajímavé je, že snad vždy se pro tento směrovač používá starší (a dnes již nevhodná) terminologie - říká se mu brána, anglicky gateway. Většinou "výchozí brána", resp. default gateway, protože přes ni jsou přenášeny všechny pakety směřující ven z dané sítě, pokud není známo že by měly jít jinou cestou. Příklad nastavení takovéto výchozí brány na počítači s OS Windows ukazuje následující obrázek.
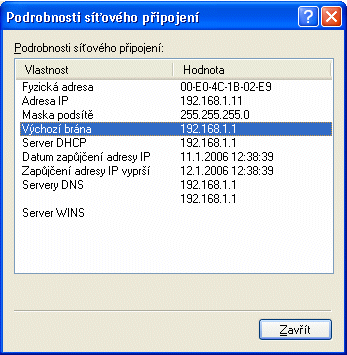 |
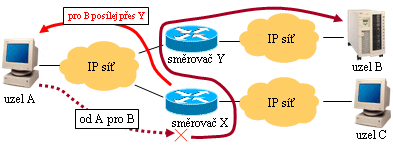
Pokud ovšem výchozí směrovač (výchozí brána) není pro konkrétní cílovou síť tím správným, měl by to on sám poznat a měl by odesílající koncový uzel zpětně informovat o této skutečnosti. Tedy poslat mu vyrozumění ve smyslu: "data, určená pro uzel B, posíláš přes mne nesprávně. Správně by měla přecházet přes směrovač Y, který je ve tvém dosahu".
Odesílající uzel, který dostane takovéto "ponaučení", by si jej měl vzít k srdci, a měl by se podle něj chovat - příště by už měl svá data posílat přes správný směrovač. Přitom směrovač, který se nachází v nesprávném směru, by neměl již přijatá data zahodit. Právě naopak, měl by být co nejvíce tolerantní a postarat se o jejich správné doručení. A to i v případě, že si jejich odesilatel nevezme jeho ponaučení k srdci a data stále posílá nesprávným směrem. To vše ale neplatí obecně, nýbrž jen v rámci sítí na bázi protokolů TCP/IP.
 |
Směrovací tabulky
K tomu, aby se směrovače mohly snáze a rychleji rozhodovat, udržují si potřebné (směrovací) informace v tzv. směrovacích tabulkách. Jejich obsah, resp. organizace, se může lišit, ale v nejjednodušším případě je takový, jak jej ukazuje následující obrázek č. 9: každé jednotlivá položka směrovací tabulky je vyhrazena jedné cílové síti. Součástí položky je pak i informace o tom, jak je cílová síť daleko, a hlavně kudy (kterým "odchozím" směrem) je třeba paket předat, aby se dostal blíže k cílové síti (neboli: kudy pokračuje cesta k této cílové síti).
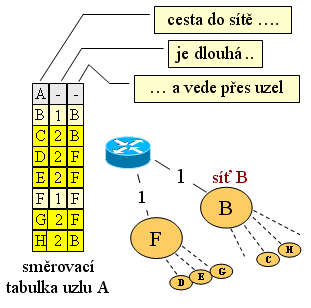 |
S popisovaným obsahem směrovacích tabulek souvisí ještě jedna důležitá skutečnost: směrování, jako rozhodování o dalším směru přenosu, vychází z příslušnosti cílového uzlu k určité síti. Jinými slovy: směruje se podle sítě, a nikoli podle konkrétního uzlu. Proto také jsou jednotlivé položky směrovacích tabulek (alespoň v TCP/IP) vyhrazeny celým cílovým sítím, a nikoli jednotlivým uzlům v těchto cílových sítích. Jinak by totiž počty položek ohromně narostly. Odpovídá to ostatně i rozdílu mezi přímým a nepřímým směrováním: po celé trase přenosu probíhá nepřímé směrování, a v každém kroku se zajišťuje přenos do další sítě jako takové (jako celku). Teprve v poslední (cílové) síti se již nejedná o nepřímé směrování, ale o směrování přímé (v rámci dané sítě). Zde už tedy směrovací tabulka není zapotřebí, protože doručení konkrétnímu uzlu v cílové síti zajistí zdejší linková vrstva.
Existence směrovacích tabulek se přitom netýká pouze směrovačů. Mají je i koncové uzly, protože i ony se podle nich musí rozhodovat při odesílání, přes který "odchozí" směrovač data poslat. Jejich směrovací tabulky ale bývají v praxi podstatně menší. Základem jejich obsahu je informace o existenci výchozí brány, kterou jsme si popisovali výše. Další položky pak do směrovací tabulky koncového uzlu přibývají obvykle postupně, na základě "upozornění" od směrovače, že správný směr vede jinudy (přes jiný směrovač, viz výše).
Adaptivní a neadaptivní směrování
Pojďme nyní k jinému důležitému aspektu: kdo a jak stanovuje a aktualizuje obsah směrovacích tabulek směrovačů? Zde už to totiž je komplikovanější, než u koncových uzlů.
V úvahu zde připadají dvě základní možnosti:
- "neadaptivní": obsah směrovacích tabulek (směrovačů) je dán apriorně a nemění se. Pak jej může jednorázově stanovit například správce sítě, a veškeré směrování bude následně fungovat vždy stejně.
- "adaptivní": směrovací tabulky směrovačů jsou na počátku nějak nastaveny, ale jejich obsah se průběžně aktualizuje, tak aby odrážel topologii soustavy sítí a reagoval na její změny.
Každá z těchto dvou variant samozřejmě má své výhody, ale i své nevýhody. Neadaptivní varianta nemá žádnou režii na své průběžné udržování (když k němu nedochází), a je také více odolná vůči eventuelním útokům, které by se snažily mechanismus směrování nějak nabourat. Proto se používá například tam, kde jsou zvýšené požadavky na bezpečnost. Nevýhodou neadaptivní varianty je ale její neschopnost reagovat na změny v síti a její topologii. To při zvýšených požadavcích na bezpečnost může být i výhodou, ale obecně je to nevýhodou, kvůli které lze tuto variantu doporučit jen tam, kde lze předpokládat zcela ojedinělé změny v topologii.
Naproti tomu adaptivní varianta přímo počítá s tím, že bude na eventuelní změny v topologii reagovat. Takže ji lze využít i tam, kde ke změnám dochází relativně častěji. Důležité ovšem je, že s touto adaptivností může být spojena i poměrně velká režie, na výměnu aktualizačních informací (informací o změnách v síti). Zde velmi záleží na tom, jaké varianty směrování (a výměny směrovacích informací) jsou konkrétně použity. Pojďme se proto podívat, jaké možnosti zde připadají v úvahu.
Centralizované směrování
Začněme nejprve poněkud specifickou variantou, označovanou jako centralizované směrování. Jde o řešení, v rámci kterého veškeré rozhodování (o volbě nejvhodnější cesty) provádí jeden centrální prvek, zatímco všechny směrovače již jen mechanicky naplňují jeho rozhodnutí. Lze si to představit také tak, že jednotlivé směrovače přestanou samy přemýšlet, a kdykoli neví co a jak mají dělat, zeptají se centrálního prvku. Tomu se říká "route server", což by se dalo rozepsat jako "server, poskytující jako svou službu informace o cestách". Na konkrétní dotaz tento server odpoví, a směrovač se podle toho zachová. A aby se při dalším paketu nemusel ptát hned znovu, a příliš tak nezatěžoval route server, každou odpověď si po nějakou dobu pamatuje ve své vyrovnávací paměti a podle ní se řídí. Tato doba přitom musí být volena velmi pečlivě. Kdyby totiž byla příliš krátká, pak by se směrovač ptal příliš často a příliš by zatěžoval route server. Naopak, když bude moc dlouhá, hrozí nebezpečí že směrovač nebude včas reagovat na nějakou změnu v topologii. Stále totiž bude vycházet z předchozí odpovědi route serveru, místo toho aby si vyžádal odpověď novou, která by již odrážela příslušnou změnu.
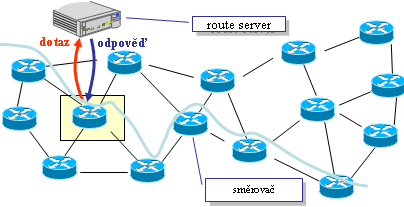 |
Výhodou centralizovaného směrování je nulová režie na aktualizační informace, kterými by se jednotlivé směrovače jinak vzájemně informovaly o změnách. Další významnou výhodou je i soustředění veškeré "inteligence" do jednoho místa, což usnadňuje systémovou správu. Na druhou stranu zde ale vzniká "klíčové místo", s jehož výpadkem se celá soustava vzájemně propojených sítí stává nefunkční - jednotlivé směrovače se pak vůbec nedozví, do a jak mají dělat.
Izolované směrování
Další variantou směrování, vedle centralizovaného, je směrování označované jako izolované. To proto, že zde už se rozhodují jednotlivé směrovače, ale skutečně jen samy za sebe, aniž by přitom spolupracovaly s ostatními. Proto přívlastek "izolované".
Jde ovšem o celou skupinu různých dílčích variant, mezi které patří mj.:
- záplavové směrování
- směrování metodou horké brambory
- náhodné směrování
- metoda zpětného učení
a další. Například záplavové směrování, které je v praxi relativně často používané, funguje skutečně tak jak naznačuje jeho název: každý směrovač rozešle přijatý paket do všech směrů, kromě toho odkud přišel. Tím vzniká jakási záplava, která dříve či později dorazí na místo svého správného určení. Současně je ale nutné správně a korektně eliminovat duplicitní pakety, které při záplavovém rozesílání vznikají, aby na místo svého určení dorazil každý paket jen jednou. Výhodou je velká robustnost - pokud existuje alespoň nějaká cesta k cíli, je tímto způsobem nalezena. A vlastně bez toho, aby směrovače vůbec potřebovaly nějaké směrovací tabulky.
Pro zajímavost se zmiňme ještě o metodě horké brambory. Ta se začíná používat (jako náhradní varianta) v situaci, kdy jinak používané směrování se dostává do problémů a směrovači hrozí zahlcení. Když se v některém odchozím směru začínají hromadit pakety, které směrovač nestíhá odeslat, může nastoupit právě směrování metodou horké brambory - směrovač volí odchozí směr nikoli podle toho, kudy by měl paket správně pokračovat, ale podle toho, který odchozí směr je právě nejméně vytížený (tj. kde se "horké brambory" dokáže co nejrychleji zbavit). Když se pak nebezpečí zahlcení podaří odvrátit, směrovač se zase vrací ke svému původnímu způsobu směrování.
Distribuované směrování
V praxi nejčastěji používané varianty směrování však spadají do kategorie "distribuovaných". To proto, že zde není žádný centrální prvek, který by o volbě směru rozhodoval (jako je tomu u centralizovaného směrování), ale celé rozhodování je rozděleno (distribuováno) mezi jednotlivé uzly, které na něm spolupracují (což je zase odlišnost od izolovaného směrování).
Jednou z variant distribuovaného směrování je takové, které je v angličtině označováno jako "vector-distance". To proto, že sousední směrovače si mezi sebou vyměňují celé své směrovací tabulky, i s jejich obsahem (viz výše). Každou položku směrovací tabulky si přitom lze představit jako vektor, který říká že z určitého směrovače se lze dostat do konkrétní cílové sítě takovým a takovým směrem, a že tato síť je tak a tak daleko. Když se pak nějaký směrovač dozví, ze směrovací tabulky svého souseda, že ten je vzdálen od určité cílové sítě X na Y jednotek, připočítá si k tomu svou vzdálenost od souseda, a vyjde mu že on se do sítě X dostane (přes svého souseda) se vzdáleností Y+1 jednotek (například). Právě toto je princip fungování varianty "vector distance", která je v praxi (v sítích TCP/IP) realizována například protokolem RIP (Routing Information Protocol). Ten je ale již poměrně staršího data, a v praxi se tolik nepoužívá.
Používanějším je protokol OSPF (Open Shortest Path First), který ale spadá pod jinou variantu - nikoli již "vector distance", ale "link state". To proto, že zde už si jednotlivé směrovače neposílají mezi sebou žádné vektory se vzdálenostmi, resp. celé své směrovací tabulky. Místo toho si posílají pouze informace o tom, že někde existuje nějaké spojení mezi dvěma uzly (směrovači), a je funkční. Každý směrovač uzel rozešle do celé soustavy vzájemně propojených sítí (obvykle pomocí záplavového směrování) informaci o tom, kdo jsou jeho sousedé a zda jsou pro něj dosažitelní (zda spojení mezi nimi funguje). Ostatní směrovače, když takto "posbírají" informace o sousedech všech ostatních směrovačů, získají ucelenou představu o skutečné topologii celé soustavy sítí, a mohou si také samy vypočítat nejvhodnější cestu, odkudkoli kamkoli. Důležité také je, že aktualizační informace pak stačí posílat jen při nějaké změně (výpadku spojení, či naopak zřízení nějakého nového spojení mezi dvěma směrovači). Díky tomu je režie na průběžné šíření aktualizačních informací výrazně menší, než u variant "vector distance" - a tak je směrování "link state" (s protokolem OSPF) v praxi použitelné i pro podstatně větší sítě, než první varianta (s protokolem RIP).