


Počítačové sítě jako důsledek vývoje
Tento článek vyšel v počítačových novinách Computerworld č. 12 z roku 1994, jako tzv. Téma týdne.
Obsah:
- Dávky a dávkové zpracování
- Výhody dávkového zpracování
- Sdílení času
- Důsledky sdílení času
- Terminálové sítě
- Terminálové relace
- Vzdálené přihlašování
- Tři hlavní úkoly budování počítačových sítí
- Velká počítačová revoluce
- Od minipočítačů k osobním počítačům
- Aplikace se stěhují ...
- Od extrému k extrému ...
- Osobní počítače v roli terminálů
- Potřeba transparentního sdílení
- Pokroky v přenosových technologiích
- Model klient/server
- Sítě serverového typu a sítě peer-to-peer
- Není LAN jako WAN! (?)
Počítače mají za sebou již téměř padesátiletou historii. Za tu dobu prošly významým vývojem - zcela zásadně se změnily jejich schopnosti, kapacitní možnosti i způsob jejich využívání. Výrazně se však měnil i vztah člověka k výpočetní technice: jestliže v určité fázi lidé usoudili, že je výhodné přejít od velkých střediskových počítačů s výrazně centralizovanou koncepcí ke zcela decentralizovaným osobním počítačům, po určité době si uvědomili, že ani tento extrém není nejvýhodnější, a začali hledat zlatou střední cestu. Přitom přišli na to, že počítače je možné vzájemně propojovat do sítí .....
První počítače, které vznikly v období kolem druhé světové války a bezprostředně po ní (viz Téma týdne, CW 6/94), bychom z dnešního pohledu mohli považovat spíše za poněkud objemnější programovatelné kalkulačky - alespoň pokud jde o jejich schopnosti, hodnocené podle současných měřítek. Byly ovšem zcela nezbytným předstupněm, bez kterého bychom dnes neměli žádné osobní počítače, žádné sítě, a dokonce ani žádné počítačové hry!
V pionýrských dobách výpočetní techniky byly všechny počítače především složitými technickými zařízeními. Báječní muži od počítacích strojů, kteří se kolem nich pohybovali, byli z dnešního pohledu spíše techniky - rozuměli konstrukci svého stroje a starali se zejména o to, aby vůbec fungoval. Nezřídka to byly přímo lidé, kteří celý počítač od základů vymysleli a zkonstruovali, a když bylo třeba, dokázali jej i potřebným způsobem naprogramovat. Úlohy, které se v té době řešily, měly většinou povahu vědecko-technických výpočtů, a jejich algoritmická stránka nebývala nijak náročná: relativně nejsložitějším úkolem bylo vyjádřit postup výpočtu takovým způsobem, aby mu počítač rozumněl.
Ten, kdo v těchto pionýrských dobách potřeboval na počítači něco skutečně spočítat, si nejspíše zašel za báječnými muži od počítacích strojů, sdělil jim svou představu, a oni se již sami postarali o vše potřebné, včetně naprogramování. Nebo jej zasvětili do potřebných tajů a souvislostí, a dále postupovali společně. Dokud se vše odehrávalo spíše na experimentální bázi, v malém rozsahu a v zápalu nadšení pro věc, bylo to možné.
Jakmile se ale počítače staly výkonnějšími a složitějšími, a současně s tím ztratily své experimentální postavení, muselo se nutně změnit i jejich "lidské okolí". O fungování počítače jako takového (tedy po technické stránce) se nadále starali specializovaní technici, kteří ale již neměli příliš času zabývat se programováním a vším, co s tím souvisí. Také to již zdaleka nebyli ti, kdo počítač vymysleli, a často ani ti, kteří jej vyrobili. Tvorbou programů se také zabývali jiní lidé, kteří zase na oplátku nemuseli rozumět počítači po technické stránce. Z dnešního pohledu bychom je označili nejspíše za analytiky a programátory současně - tato kumulace u nich byla možná zejména proto, že řešené úlohy ještě nebyly tak náročné, aby si jejich analýza a algoritmizace vyžádala užší specializaci. K tomu však také časem došlo.
Ještě dříve však došlo k jiné dělbě práce: s nástupem operačních systémů přestaly aplikační (resp. uživatelské) programy pracovat přímo "na holém železe" - tedy tak, aby měly přímý a bezprostřední kontakt se všemi technickými prostředky počítače (pamětí, vstupně/výstupními zařízeními, mechanismem přerušení atd.), které by si také musely samy obsluhovat. Toto "holé železo" bylo překryto a obsluhováno jinými programy systémového charakteru (tvořícími součást operačního systému), a teprve ty pak zprostředkovávaly aplikačním programům potřebné funkce, realizované technickými prostředky. Aplikační programy nyní již nemohly počítat s tím, že jsou na počítači samy, a podle toho se také chovat - musely se naopak přizpůsobit operačnímu systému počítače, který jim vytvářel určité prostředí a podmínky pro jejich práci. S tím pak souvisela i specializace lidí, kteří se zabývali programovým vybavením: někteří z nich se museli starat o operační systém a systémové prostředky, zatímco jiní se zaměřili na vlastní aplikace, které byly v daném systémovém prostředí provozovány.
Teprve později, když se provozované aplikace staly podstatně náročnějšími, došlo k dalšímu štěpení i na tomto poli: o analýzu a algoritmizaci aplikačních úloh se starali analytici, a o jejich naprogramování aplikační programátoři.
Dávky a dávkové zpracování
S rozvojem schopností výpočetní techniky samozřejmě rychle rostl i zájem uživatelů o jejich využití. Z technických i ekonomických důvodů však ještě zdaleka nebylo možné, aby si každý uživatel mohl pořídit vlastní počítač - místo toho bylo nutné zařídit věci tak, aby jeden počítač mohl sloužit potřebám více uživatelům. Otázkou ovšem bylo, jak to udělat co možná nejefektivněji?
Kritérium efektivnosti přitom nutně muselo vycházet z obrovské ceny tehdejších počítačů, a jednoznačně tedy vedlo na to, aby počítač jako celek i jeho jednotlivé části byly využívány co možná nejintenzivněji, bez zbytečných prostojů a pro "užitečné" činnosti.
Jako nejjednodušší řešení se nabízelo přidělovat postupně celý počítač jednotlivým úlohám - tedy zařídit vše tak, aby se celý počítač nejprve věnoval provedení jedné úlohy, po jejím dokončení pak druhé úloze atd.
Efektivnosti takovéhoto řešení ovšem poněkud překvapivě stál v cestě člověk-uživatel: pokud by totiž měl mít přímý kontakt se svou úlohou a možnost bezprostředně reagovat na průběh jejího výpočtu, pak by nutně muselo docházet k situacím, kdy by celý počítač pasivně čekal na jeho reakci. No a vzhledem k ohromné disproporci mezi rychlostí počítače a rychlostí reakce člověka by to pro počítač znamenalo velké, a hlavně zcela "neužitečné" prostoje.
Historicky nejstarší metoda sdílení výpočetní kapacity více uživateli (tzv. dávkové zpracování, batch processing) je proto založena na zdánlivě paradoxní myšlence: uživatele je třeba důsledně odstavit od jeho úlohy. Neboli: zařídit věci tak, aby při vlastním provádění úlohy se již nebylo třeba uživatele na cokoli dotazovat (resp. čekat na jakoukoli jeho reakci), a celý výpočet mohl probíhat maximální možnou rychlostí.
K tomu je ovšem nutné, aby uživatel vše potřebné "řekl" předem: aby předem stanovil, co přesně se má s jeho úlohou udělat, jaká mají být její vstupní data, resp. odkud se mají vzít, co se má stát s výstupními daty, co se má dít v případě chyby apod. Pokyny, předem určující konkrétní postup při provádění jeho úlohy, musel uživatel samozřejmě vyjádřit v takové formě, která byla pro počítač srozumitelná - pomocí příkazů vhodného řídícího jazyka - a ty pak přidat k vlastní úloze a jejím datům. Tím vznikl celek, kterému se říkalo dávka (batch), a který mohl být samostatně zpracován bez přímé účasti uživatele.
Jakým konkrétním způsobem se ale dávky připravovaly, a jak se dostávaly do počítače ke zpracování?
Jednotlivé dávky byly obvykle připravovány na pořizovacích zařízeních, pracujících v tzv. nespřaženém (off-line režimu), a tedy zcela nezávislé na vlastním počítači. Nejčastěji šlo o různé děrovače, takže vlastní dávka pak mohla mít formu série děrných štítků či role děrné pásky. Ke stejnému účelu se však používaly například i magnetické pásky, později pak i diskety. Vesměs však byly dávky zaznamenávány na nosiče, které bylo třeba fyzicky přinést až k odpovídajícímu vstupnímu zařízení (snímači štítků či děrné pásky apod.), odkud pak již dávka vstupovala přímo do počítače. Ten si jednotlivé dávky načítal buď okamžitě a ukládal je do fronty, realizované v jeho paměti, nebo se mu nosiče s jednotlivými dávkami v určitém pořadí hromadily v příslušném vstupním zařízení, a počítač si je skutečně načítal až v okamžiku, kdy je začínal zpracovávat.
Také výstupy, vzniklé zpracováním jednotlivých dávek, se do okolního světa dostávaly přes vhodná výstupní zařízení (děrovače, tiskárny apod.).
Dokonalejším a pružnějším řešením bylo použití tzv. dávkových terminálů. Tyto byly vhodnou kombinací vstupního a výstupního zařízení, určeného pro vstup dávek na fyzických nosičích a pro analogický výstup. Navíc ale byly vybavovány takovými komunikačními schopnostmi, které umožňovaly připojit je k vlastnímu počítači (a to i na větší vzdálenosti) po vhodných komunikačních linkách. Velmi často byly tyto dávkové terminály schopné fungovat současně i jako pořizovače dat. Jejich představu ilustruje obr. 1.
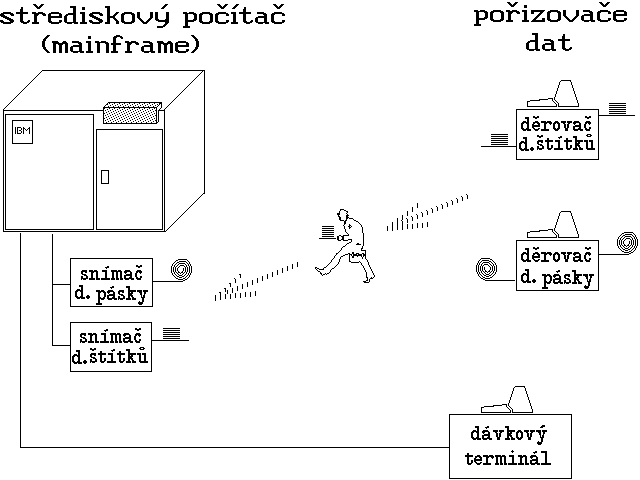 Obr. 1.: Uspořádání pro potřeby dávkového zpracování
Obr. 1.: Uspořádání pro potřeby dávkového zpracováníVýhody dávkového zpracování
Hlavním cílem zpracovávání uživatelských úloh ve formě dávek (neboli tzv. dávkového zpracování, batch processing) tedy bylo co možná nejlépe využít všech dostupných zdrojů, které byly k dispozici - především pak procesoru, který byl rozhodující (a také nejdražší) částí tehdejších počítačů. Průběžné naplňování tohoto cíle měl na starosti operační systém, který rozhodoval o tom, kdy a jak bude která dávka zpracována, resp. kdy jí bude přidělen určitý systémový zdroj, který ke svému provedení vyžadovala (což byl nejčastěji procesor, ale například také určité konkrétní vstupní či výstupní zařízení). Samotná koncepce dávek vycházela tomuto úkolu vstříc tím, že eliminovala bezprostřední interakci uživatele s jeho úlohou, a tím dávala operačnímu systému mnohem širší prostor pro nejrůznější optimalizační postupy.
Nejvýznamnějším optimalizačním postupem byla možnost souběžného provádění více úloh, které pracovaly s různými systémovými zdroji: jestliže se například právě prováděná úloha rozhodla zahájit určitou vstupně/výstupní operaci a čekat na její dokončení, pak tato operace obvykle probíhala zcela autonomně, a nevyžadovala přímou účast procesoru. Pak ovšem bylo zcela zbytečné, aby úloha, čekající na dokončení vstupně/výstupní operace, "obsazovala" procesor a zaměstnávala jej pouze pasivním čekáním. Operační systém, veden snahou o maximálně efektivní využití procesoru, mohl takovéto úloze procesor odejmout (resp. nechat ji čekat tak, aby přitom neobsazovala procesor), a ten naopak přidělit jiné úloze, připravené ke zpracování a čekající ve frontě. Díky tomu pak mohlo vedle sebe existovat více úloh v různém stádiu rozpracovanosti: vedle právě prováděné úlohy to mohla být celá řada dalších úloh, připravených ke zpracování a čekajících jen na přidělení procesoru, a dále pak takové úlohy, které někdy dříve (jako "právě probíhající") odstartovaly nějakou vstupně/výstupní operaci, a v daném okamžiku ještě čekaly na její dokončení.
Tímto způsobem (i některými dalšími "triky", které ale již přesahují rámec tohoto textu) pak operační systém dokázal v rozumné míře vyhovět potřebám více uživatelů, a v maximální možné míře zaměstnat procesor svého počítače. V době, kdy výpočetní kapacita (určená především schopnostmi procesoru) byla velmi nákladná, to bylo právě tím, o co šlo ze všeho nejvíc.
Uživatelé chtějí okamžitou odezvu
Pro uživatele ovšem nebylo maximální vytížení procesoru zase až tak podstatné. Pro ně bylo mnohem významnější to, že neměli bezprostřední kontakt se svou úlohou, nemohli tudíž reagovat na průběh jejího výpočtu, a většinou museli i dost dlouho čekat, než vůbec dostali nějaké výsledky z jejího zpracování - nezapomeňme totiž, že o tom, kdy bude určitá úloha skutečně zpracována, nerozhodoval pouze okamžik jejího odevzdání ve formě dávky do systému dávkového zpracování, ale také celá řada dalších faktorů, včetně počtu a charakteru souběžně zadávaných či již dříve přijatých dávek.
Dávkové zpracování se tedy vůči uživatelům projevovalo zejména dlouhou dobou odezvy - neboli dobou, která uplyne od zadání určité akce do projevení se jejího efektu. Uživatel, který v dávkovém systému zpracování ladil nějaký program, zase nejvíce pociťoval dlouhou dobu obrátky, jako dobu mezi dvěma iteracemi postupného ladění své úlohy. Jistě, byla to doba skutečných programátorů, kteří raději déle přemýšleli a méně experimentovali, ale i tak pro ně dlouhá doba odezvy či obrátky byla značně nevýhodná.
Uživatelé samozřejmě volali po okamžité odezvě a možnosti průběžné interakce se svými úlohami. Uvědomme si ale dobře, co to vlastně znamenalo: schopnost okamžité odezvy vyžaduje, aby příslušná úloha měla procesor kdykoli k dispozici, a mohla tudiž ihned zareagovat na vstup uživatele. Má-li se ovšem uživatelova vstupu vůbec dočkat, musí si na něj nejprve počkat, což zase znamená, že bude "neužitečně" spotřebovávat čas procesoru.
Nejjednodušším řešením by samozřejmě bylo přidělit úloze natrvalo celý počítač - to si ale můžeme dovolit až dnes, v době mikroprocesorové techniky a osobních počítačů. Ovšem v době, kdy světu ještě vládly velké a drahé střediskové počítače, bylo něco takového nemyslitelné.
Poměrně brzy se ale ukázalo, že požadavku uživatelů na okamžitou odezvu by přeci jen šlo určitým způsobem vyhovět: kdyby se totiž jednotlivé úlohy střídaly na procesoru dostatečně rychle, například takovým způsobem, že žádná z nich nebude obsazovat procesor déle než na určitý malý a pevně daný časový interval, a počet takovýchto úloh by byl shora omezen, pak by bylo zajištěno i to, že každá úloha se dostane "ke slovu" nejpozději za předem stanovenou dobu. Díky tomu by pak mohla poměrně rychle zareagovat i na vstup uživatele - ne sice okamžitě, tedy s nulovou dobou odezvy, ale na dostatečně rychlém procesoru a při nepříliš velkém počtu souběžně zpracovávaných úlohou s tak krátkou dobou odezvy, že by její nenulovost uživatel nemusel ani zaznamenat.
Rozeberme si tuto myšlenku poněkud podrobněji: v režimu dávkového zpracování byl procesor přidělen určité úloze na tak dlouhou dobu, na jakou tato úloha dokázala procesor plně zaměstnat (resp. tento jí byl odňat v okamžiku, kdy zahájila nějakou vstupně/výstupní operaci, a v důsledku toho již přestala procesor intenzivně využívat). Později se sice i rámci dávkového zpracování začaly jednotlivé úlohy střídat na procesoru častěji, ale zdaleka ještě ne tak často, jak by bylo potřeba pro zajištění dostatečně krátké odezvy - uvědomme si ale, že v režimu dávkového zpracování, kde se á priory nepředpokládala interakce uživatele s jeho úlohou, toto nebylo vůbec cílem. Naopak, v dávkovém zpracování šlo o maximálně efektivní využití procesoru, a časté střídání úloh bylo s tímto cílem ve sporu: každé "přepnutí" z jedné úlohy na druhou bylo totiž spojeno s nenulovou režii.
Myšlenka velmi rychlého střídání úloh na jednom procesoru si proto na svou realizaci musela chvíli počkat - do té doby, než cena počítačů dostatečně poklesla a jejich rychlost naopak stoupla tak, že se režie, spojená s častým přepínáním úloh, stala únosnou.
Sdílení času
Jakmile se tedy počítače dostatečně zrychlily (a současně s tím i zlevnily), bylo možné v praxi nasadit režim, k jehož rámcové představě jsme dospěli v předchozím odstavci - režim, označovaný příznačně jako sdílení času (time sharing)
Za svůj název vděčí tomu, že jednotlivé úlohy, patřící obvykle různým uživatelům, se díky svému rychlému střídání vlastně dělí o celkový strojový čas, který je k dispozici, neboli jej sdílí - odsud "sdílení času".
Praktická realizace sdílení času je principiálně jednoduchá: každá úloha dostane přidělen procesor vždy na určitý časový interval (časové kvantum, v angličtině: time-slice), a po jeho uplynutí je procesor zase vrácen zpět operačnímu systému. Ten jej obdobným způsobem přidělí další úloze, pak další atd., dokud takto neobejde všechny úlohy, kterých se to týká, a pak začíná od znovu.
Jednotlivé úlohy mohou na tomto scénáři vědomě spolupracovat tím, že po uplynutí přiděleného časového kvanta procesor dobrovolně vrátí zpět. Je ovšem možný i opačný případ, kdy úloha procesor z vlastní iniciativy nevrací, ale tento jí musí být vždy násilím odebrán. Výhodou této tzv. preemptivní varianty je to, že příslušná úloha si vůbec nemusí uvědomovat existenci jakéhokoli střídání, a ostatně ani skutečnost, že se o čas procesoru ve skutečnosti dělí s jinými úlohami. Naproti tomu u tzv. nepreemptivní varianty si úloha tyto skutečnosti plně uvědomuje, neboť se na jejich realizaci aktivně podílí.
Zamysleme se nyní nad zajímavou otázkou: může si nějaká úloha, běžící v režimu sdílení času, dovolit pasivně čekat na vstup od uživatele? Tedy na to, až uživatel zmáčkne nějakou klávesu, zadá určitý znakový řetězec apod.? Může. Pokud při svém pasivním čekání vyčerpá právě přidělené časové kvantum a reakce uživatele se nedočká, je jí procesor zase odebrán a postupně přidělován dalším úlohám. Naše úloha tedy v nejhorším případě "proplýtvá" svá přidělená časová kvanta (které by tak jako tak sama nevyužila, dokud se požadovaného vstupu nedočká), ale ostatní úlohy tím nejsou nijak ochuzeny. Právě naopak, mohou na tom dokonce i vydělat - čekající úloha se může zachovat i tak, že v rámci čekání na začátku každého přiděleného časového kvanta si pouze jednorázově zjistí, zda vstup od uživatele je již k dispozici či nikoli, a pokud ne, vrátí procesor zpět (čímž se vlastně vzdá zbytku časového kvanta, které jí bylo právě přiděleno).
Abychom si právě vyslovené myšlenky zasadili do správného kontextu, musíme si ještě uvědomit, jak velká jsou časová kvanta, přidělovaná jednotlivým úlohám v režimu sdílení času, resp. jak často se jednotlivé úlohy "dostávají ke slovu": konkrétní hodnoty se samozřejmě mohou významněji lišit, a měnit se i v závislosti na momentální zátěži, ale vždy půjde maximálně o zlomky sekund. Z pohledu člověka a ve srovnání s rychlostí jeho reakcí jsou tyto časy záměrně voleny natolik malé, aby vytvářely iluzi nepřetržitého běhu úloh! Navíc, a to je neméně podstatné, může jeden počítač vytvářet tuto iluzi více uživatelům současně!
Důsledky sdílení času
Režim sdílení času, který jsme si právě naznačili, měl velmi závažné důsledky na přístup člověka k výpočetní technice, i na architekturu počítačů jako takových. Poprvé zavedl možnost interaktivního zpracování (jako protipólu zpracování dávkového), při kterém mohou mít uživatelé bezprostřední kontakt se svými úlohami, mohou jim průběžně zadávat své vstupy, a přejímat jejich průběžné výstupy. Možnost interaktivního zpracování doslova otevřela dveře bohaté škále nejrůznějších aplikací, jaké by ve světě dávkového zpracování neměly příliš velký smysl či alespoň postrádaly svou atraktivnost. Jak důležité to bylo, o tom svědčí fakt, že drtivá většina dnešních aplikací má vysloveně interaktivní charakter: od nejrůznějších editorů až po snad úplně všechny počítačové hry.
Provozování interaktivních aplikací si ovšem okamžitě vynutilo také zavedení vhodných uživatelských pracovišť, prostřednictvím kterých mohou uživatelé skutečně "interagovat" se svými aplikacemi. Tato uživatelská pracoviště, označovaná jako terminály, byla vždy tvořena dvojicí zařízení: jedním vstupním, kterým vždy byla klávesnice, a jedním výstupním - tím byla zpočátku tiskárna, později pak obrazovka. Velké střediskové počítače byly vybavovány desítkami takovýchto terminálů (někdy prý až stovkami), a ty pak umožňovaly současnou práci s počítačem příslušnému počtu uživatelů.
Velmi podstatná přitom byla i skutečnost, že nyní se nemusel člověk obtěžovat za počítačem - nyní tomu již mohlo být naopak: terminály, prostřednictvím kterých se s počítačem pracovalo, se mohly dostat až k jednotlivým uživatelům do jejich kanceláří, laboratoří, obchodů, úřadoven apod.
Terminálové sítě
Jednotlivé terminály se k počítačům připojovaly různými způsoby, které se navíc mohly vzájemně kombinovat. U velkých střediskových počítačů s mnoha a mnoha terminály se jednalo o celé terminálové sítě - které ale nebyly ničím jiným, než více či méně komplikovaným "rozvodem" z jednoho centra do mnoha jednotlivých míst (viz obrázek 2).
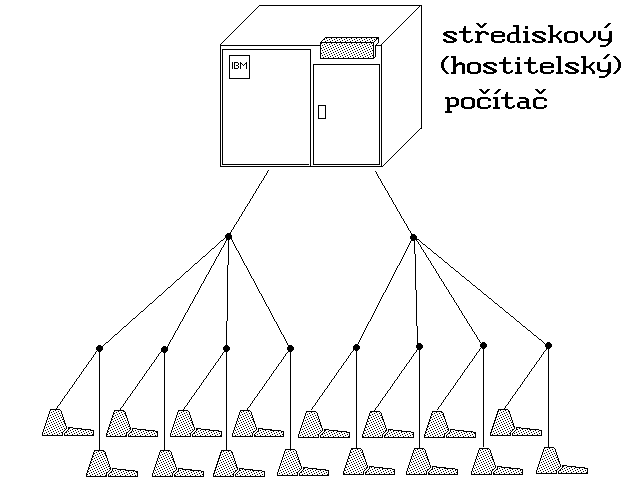 Obr. 2: Obecná představa terminálové sítě
Obr. 2: Obecná představa terminálové sítěDůležité přitom bylo to, že v rámci takovýchto terminálových sítí mohly být jednotlivé terminály připojovány jak na krátkou vzdálenost (jako tzv. místní terminály), tak i na větší až hodně velké vzdálenosti (jako tzv. vzdálené terminály) - např. v jiném městě, v jiném státě, či dokonce i na jiném kontinentě.
Některé velké počítače byly vybavovány opravdu velkými počty terminálů. Jejich terminálové sítě pak ale již byly natolik rozsáhlé, že se v nich velmi kategoricky prosadil požadavek odlehčit centrálnímu počítači, který stál v kořeni celé terminálové sítě, a zbavit jej co možná největší části povinností při obsluze terminálů - tak aby se mohl plně soustředit na vlastní provozování aplikačních a jiných programů. Proto se v rámci terminálových sítí začaly používat různé specializované složky.
Takovou specializovanou složkou (viz obr. 3) byl především tzv. komunikační řadič (communication processor). Mohl být jednoúčelovým zařízením, ale častěji byl spíše samostatným počítačem, vystupujícím v roli tzv. předřazeného procesoru (front-end processor). Jeho hlavním úkolem byl sběr dat od velkého počtu jednotlivých zdrojů a jejich předávání centrálnímu počítači, resp. distribuce dat od centrálního počítače k velkému počtu jednotlivých cílů. Přitom musel zajišťovat i spoustu dalších věcí, které souvisely s vlastním přenosem takovýchto dat oběma směry.
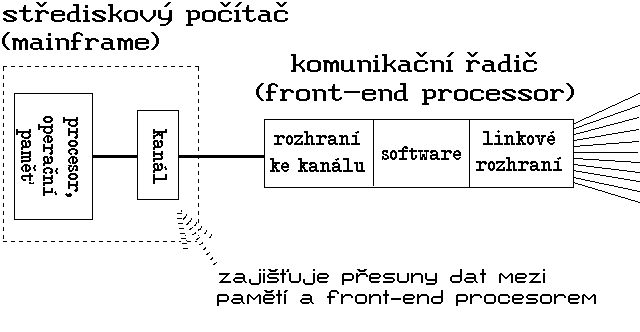 Obr. 3.: Představa komunikačního řadiče (front-end procesoru)
Obr. 3.: Představa komunikačního řadiče (front-end procesoru)Jednotlivé terminály se mohly připojovat již přímo k předřazenému procesoru (komunikačnímu řadiči) - místní pomocí vhodných kabelů, vzdálené terminály pak přes komunikační linky a s pomocí modemů, viz obr. 4. Častěji se však mezi komunikační řadič a terminály vkládal ještě jeden specializovaný prvek, tzv. terminálový řadič (někdy též: koncentrátor), který na sebe přebíral bezprostřední obsluhu celé skupiny terminálů. Výhody tohoto uspořádání byly patrné zejména při připojování celých skupin vzdálených terminálů (viz obr. 5), které díky použití společného terminálového řadiče (koncentrátoru) mohly sdílet jedinou komunikační linku, vedoucí směrem k centrálnímu počítači.
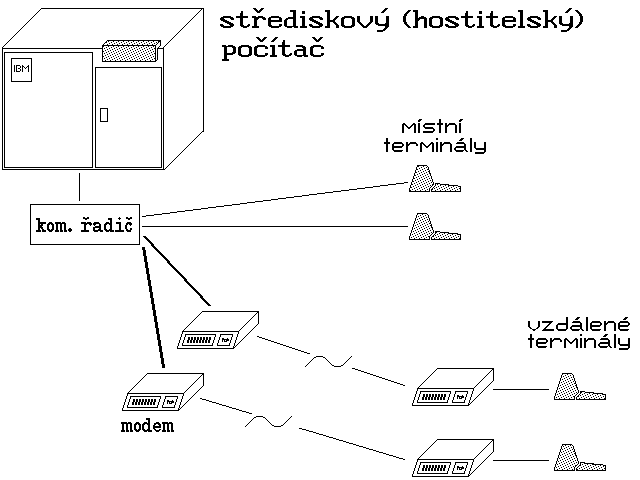 Obr. 4: Připojování terminálů přímo ke komunikačnímu řadiči
Obr. 4: Připojování terminálů přímo ke komunikačnímu řadiči
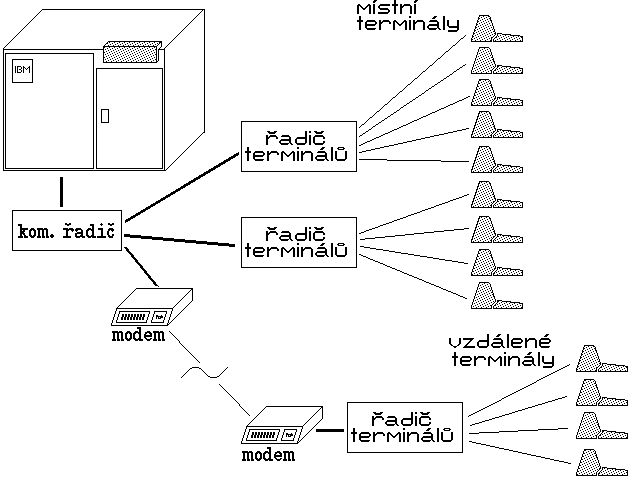 Obr. 5: připojování terminálů přes terminálové řadiče
Obr. 5: připojování terminálů přes terminálové řadičeZajímavým momentem v souvislosti s terminálovými sítěmi je skutečnost, že již tyto byly v některých případech považovány za počítačové sítě jako takové - příkladem může být zejména architektura počítačových sítí SNA (Systems Network Architecture) firmy IBM, resp. její první varianta, pocházející z roku 1974. Jako jedna z nejstarších síťových architektur SNA zpočátku chápala počítačovou sít jen jako prostředek "rozvodu" dat, s přísně hierarchickým uspořádáním dle obrázku 6, čímž vlastně kladla rovnítko mezi síť terminálovou a síť počítačovou. Až mnohem později se do architektury SNA prosadila i představa, že by bylo možné vzájemně propojovat také samotné počítače.
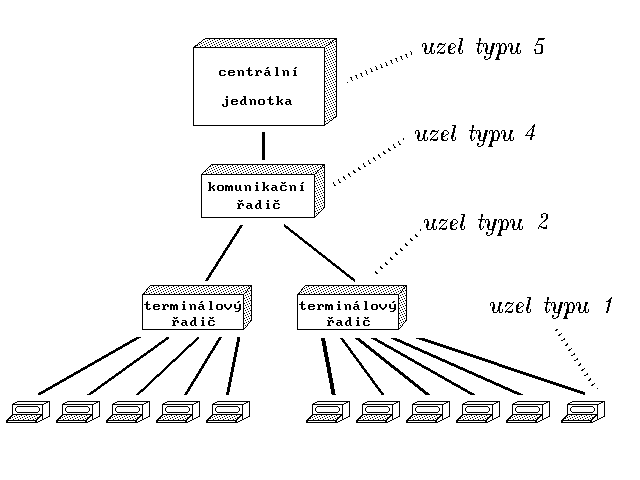 Obr. 6: Představa počítačové sítě dle první varianty architektury SNA firmy IBM
Obr. 6: Představa počítačové sítě dle první varianty architektury SNA firmy IBMSíťová architektura SNA rozděluje jednotlivé druhy uzlů do typů, které čísluje od 1 do 5 (viz obrázek). Uzly typu však 3 neexistují.
Terminálové relace
Pro správné pochopení významu a smyslu terminálů, a zvláště pak pro pochopení některých důvodů, které vedly ke vzájemnému propojování počítačů, je vhodné se podrobněji zastavit u pojmu terminálové relace.
Terminálová relace (terminal session) je vlastně dialogem mezi uživatelem a jeho úlohou. Má interaktivní charakter, a proto se objevuje vlastně až u počítačů, které interaktivní způsob práce jednotlivých uživatelů připouští - tedy až u víceuživatelských počítačů, které pracují v režimu sdílení času.
Pro zřízení (vytvoření, navázání) terminálové relace je zapotřebí, aby si uživatel sedl k určitému konkrétnímu terminálu, a z něj se přihlásil do systému - provedl tzv. počáteční přihlášení (anglicky: login). V rámci tohoto úkonu uživatel sdělí operačnímu systému svou identitu (vyjádřenou svým uživatelským jménem), a zadáním správného hesla pak prokáže, že je skutečně tím, za koho se vydává. Operační systém pak již povede v patrnosti, že všechny vstupy, které mu bude uživatel zadávat, budou přicházet právě z toho terminálu, ze kterého se uživatel přihlásil, a naopak že veškeré výstupy, určené danému uživateli, mu musí být zasílány na tentýž termminál. Tuto informaci operační systém předá každé úloze, kterou si dotyčný uživatel ze svého terminálu spustí: po přihlášení to bude tzv. interpret příkazů, neboli úloha systémového charakteru, prostřednictvím které uživatel zadává příkazy operačnímu systému, a také spouští další úlohy, například různé aplikační úlohy apod. Všechny úlohy, které si tento uživatel spustí, přitom musí respektovat konvenci o tom, že se svým uživatelem komunikují přes příslušný terminál - no a právě to je podstatou terminálové relace, která vzniká s přihlášením uživatele do systému, a naopak zaniká při jeho odhlášení.
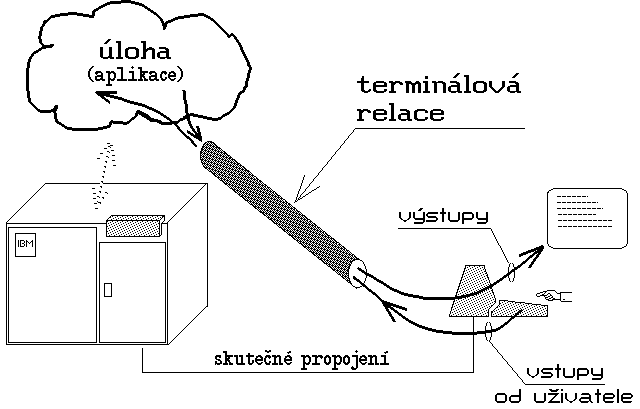 Obr. 7.: Představa terminálové relace
Obr. 7.: Představa terminálové relacePro ještě názornější představu je možné přirovnat terminálovou relaci k rouře, která vede od počítače k terminálu, u kterého uživatel pracuje, a kterou proudí veškerá data, která si uživatel a jeho úloha vzájemně předávají. Přirovnání k pomyslné rouře je navíc vhodné i pro pochopení skutečnosti, kterou některé počítače (resp. jejich operační systémy) připouští: totiž že uživatel si z jednoho a téhož terminálu zřídí hned několik terminálových relací. Ty si můžeme stále představovat jako pomyslné roury, ovšem s tím, že v daném okamžiku je vždy jen jedna z nich aktivní - tedy že v daném okamžiku jen jedna z nich na straně uživatele skutečně "ústí" do obrazovky (a klávesnice) příslušného terminálu, zatímco ostatní roury momentálně končí "naprázdno" (a v důsledku toho jimi právě nemohou proudit žádná data). Uživatel přitom musí mít možnost si ze svého terminálu volit, která relace má být právě aktivní - může se tedy mezi jednotlivými relacemi podle potřeb přepínat. V rámci každé terminálové relace přitom jeden a tentýž uživatel může mít spouštěnu samostatnou úlohu, která díky režimu sdílení času "počítá" i v době, kdy jí příslušná terminálová relace není právě aktivní. Uživatel se přitom může mezi jednotlivými relacemi (a tím i mezi jednotlivými úlohami) podle potřeb přepínat.
Model host/terminál
Střediskové počítače, vybavené sítěmi terminálů, provozované v režimu sdílení času a sloužící více uživatelům současně, měly jeden velmi důležitý koncepční rys: byly důsledně centralistické. Prakticky všechny systémové zdroje soustřeďovaly do jediného centra, kterým byl samotný střediskový počítač. Tento fakt se přitom týkal jak objektů hardwarové povahy (od nejrůznějších periferních zařízení přes vnější paměti, operační paměť až po procesor), tak i objektů povahy softwarové - tedy všech systémových i aplikačních programů, datových souborů, databází atd. Střediskový počítač, který v sobě tyto zdroje soustřeďoval, byl v jistém smyslu jejich hostitelem. Proto se mu také v angličtině začalo říkat host computer, zkráceně pak pouze host (neboť anglické host v překladu znamená právě "hostitel").
Označení "hostitelský počítač" - jak zní obvyklý, i když nepříliš šťastný překlad anglického host computer - pak přežilo i samotné střediskové počítače. Není pro něj totiž podstatné to, zda daný počítač je velký, hodně velký či naopak pomenší, od jakého je výrobce či kdy byl vyroben. Podstatné je pouze to, jakým způsobem je využíván: jako centrální počítač se soustředěnými systémovými zdroji, na kterém jsou přímo provozovány i aplikační úlohy koncových uživatelů. Hostitelskými počítači proto byly i tzv. minipočítače, které časem začaly konkurovat střediskovým počítačům (od kterých se ale svou koncepcí a způsobem využití příliš nelišily). Hostitelskými počítači však mohou být i některé nejmodernější počítače současnosti - skutečně totiž záleží jen na tom, jakým způsobem jsou využívány.
Co je tedy ale rozhodujícím kritériem pro to, aby určitý počítač vystupoval v roli hostitelského počítače?
Skutečnost, že "hostí" různé systémové zdroje, nemusí být rozhodující, neboť nějaké zdroje dnes "hostí" opravdu každý počítač. Skutečně podstatné je to, že všechny aplikační úlohy jsou provozovány přímo na daném počítači, a koncoví uživatelé komunikují se svými úlohami prostřednictvím terminálových relací (a tedy z příslušných terminálů). Takovýto způsob provozování aplikačních úloh (který jsme ostatně až doposud předpokládali), je pak označován jako model host/terminál (ve smyslu: hostitelský počítač/terminál).
Hostitelský počítač je tedy takový počítač, který je provozován podle modelu host/terminál. Poměrně dlouhou dobu to byla jediná obvyklá možnost - ale jen do té doby, než se na obzoru objevil první alternativní model klient/server. Ale to bychom zbytečně předbíhali .....
Počátky propojování hostitelských počítačů
Když lidé zjistili, že připojovat terminály lze i na poměrně velké vzdálenosti, muselo je zákonitě napadnout i to, že přesně stejným způsobem by mělo být možné propojovat i hostitelské počítače jako takové. Dnes lze již těžko zjistit, kdo to udělal jako první, a položil tak základ skutečným počítačovým sítím.
Vcelku dobře se ale dá odhadnout motivace, která k těmto krokům vedla.
Snad největší zájem měli uživatelé o přenos dat z jednoho počítače na druhý. Zatímco až doposud se data musela přenášet v zásadě nespřaženým (off-line) způsobem, prostřednictvím fyzického přenosu nejrůznějších nosičů, nyní se již otevírala možnost jejich přenosu v elektronické formě, tzv. spřaženým (on-line) přenosem.
Přenosové cesty, které tehdy byly k dispozici, však nenabízely příliš velkou přenosovou kapacitu. Ta vcelku postačovala pro připojování vzdálených terminálů (v rámci počítačových sítí), ale pokud bylo třeba přenášet větší objemy dat, nastávaly problémy. Proto se první přenosy dat mezi hostitelskými počítači odehrávaly vesměs dávkovým způsobem, formou přenosu celých souborů. Zajímavé je, že tato služba (tj. přenos souborů) stále dominuje i v dnešních rozlehlých sítích. Například podle statistik z roku 1992 představoval v celém Internetu přenos souborů celkem 50% veškerého datového provozu. Tedy vlastně tolik, jako všechny ostatní služby dohromady.
Vzdálené přihlašování
V okamžiku, kdy došlo ke vzájemnému propojení hostitelských počítačů, se na obzoru objevila nová, dosud netušená možnost: možnost vzdáleného přihlašování (remote login), realizovaná prostřednictvím tzv. vzdálených terminálových relací (remote terminal sessions). O co vlastně šlo?
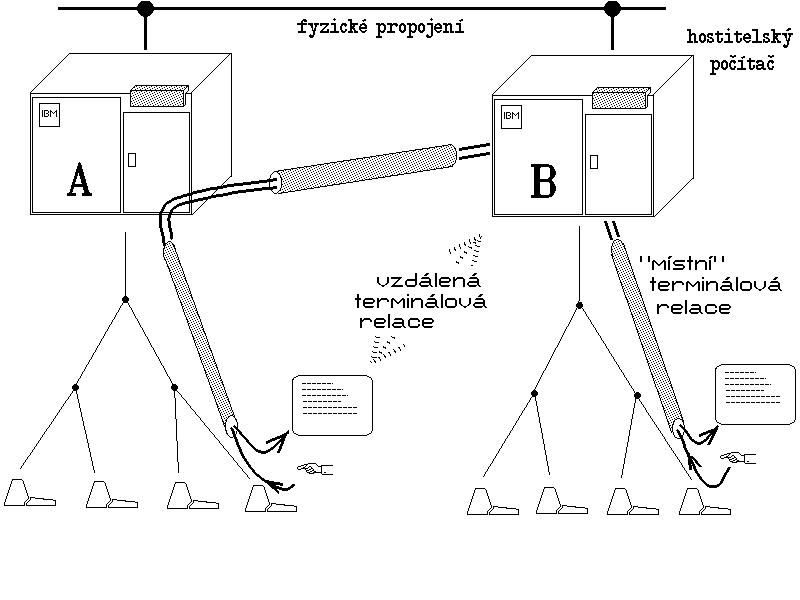 Obr. 8.: Představa vzdálených terminálových relací
Obr. 8.: Představa vzdálených terminálových relací
Představme si, v souladu s obrázkem 8, dva hostitelské počítače A a B s vlastními terminálovými sítěmi. Dále předpokládejme, že tyto dva počítače jsou vzájemně propojeny - a nachází se například každý v jiném městě. Nyní si představme uživatele, který si sedne k jednomu z terminálů počítače A. Standardní úkon, který provede, je že se přihlásí operačnímu systému počítače A (provede tzv. login, viz výše), a tím si nechá zřídit terminálovou relaci s počítačem A. Využijeme-li naší představu terminálové relace jako pomyslné roury, pak takto zřízená relace-roura přenáší všechny vstupy od uživatele (z jeho terminálu) až do počítače A, kde je přijímá právě běžící úloha (kterou bude ihned po navázání relace již dříve zmiňovaný interpret příkazů). Nyní ale ten podstatný moment: jsou-li oba počítače vzájemně propojeny, není principiální problém zařídit věci tak, aby vstupy od uživatele "nekončily" na počítači A, ale byly přenášeny až do počítače B (analogicky pak pro výstupy, putující opačným směrem). Jinými slovy: lze zařídit, aby pomyslná roura, reprezentující terminálovou relaci, přes počítač A pouze procházela, a vedla až do počítače B. Tedy aby se uživatel ze svého terminálu (který je fyzicky připojen k počítači A) mohl přihlásit operačnímu systému počítače B (provést tzv. login na počítači B), a tím si nechal zřídit terminálovou relaci s počítačem B.
Zastavme se na chvilku u důsledků, které toto řešení přináší: relace, kterou si uživatel počítače A nechá zřídit s počítačem B je tzv. vzdálenou terminálovou relací (ve smyslu: terminálovou relací se vzdáleným počítačem). Toho, kdo si ji zřídí, vlastně staví do stejného postavení, jako skutečného uživatele onoho vzdáleného počítače (míněno: uživatele, který sedí u místního terminálu tohoto počítače). Prostřednictvím vzdálené terminálové relace se tak uživatel jednoho počítače může "na dálku" přihlásit do operačního systému vzdáleného počítače (provést tzv. vzdálené přihlášení, remote login), a dále již pokračovat naprosto stejně, jako kdyby skutečně seděl u místního terminálu tohoto počítače.
Pravdou je, že ono "naprosto stejně" může být někdy poněkud nadsazené - ne ani tak z pohledu postavení uživatele a jeho princiálních možností, jako kvůli rychlosti odezvy. Ta je totiž u vzdálených terminálových relací vždy závislá také na "průchodnosti" propojení příslušných počítačů, a tato je vždy nějakým způsobem omezena. Zvláště v době, kdy dostupné komunikační linky nabízely jen relativně malou přenosovou kapacitu, museli se uživatelé občas vyzbrojit dostatečnou mírou trpělivosti. Ale měli proč: díky možnosti vzdáleného přihlašování mohli pracovat "na dálku" na počítačích, které od nich byly často velmi vzdáleny, aniž by za nimi museli často dlouho a s nemalými náklady cestovat.
Vzdálené terminálové relace, a jimi zprostředkovaná možnost vzdáleného přihlašování, se tak staly mechanismem pro široké zpřístupnění výpočetní kapacity, resp. pro její sdílení širším okruhem uživatelů. Současně s tím se ale staly i prostředkem pro poskytování dalších služeb - vždyť prostřednictvím vzdálených terminálových relací mohou uživatelé jiných počítačů využívat většinu toho, co je na daném počítači k dispozici: od nejrůznějších aplikací až po datové soubory a databáze.
Tři hlavní úkoly budování počítačových sítí
Budování počítačových sítí, zahájené vzájemným propojováním hostitelských počítačů, velmi brzy prokázalo své opodstatnění, a naznačilo dříve netušené potenciální možnosti. Proto se této oblasti začala věnovat adekvátní pozornost (včetně finančních prostředků), a ze spíše experimentálního přístupu k věci se začalo uvažovat i o komerčním využití.
Mezitím již také dostatečně vykrystalizovala představa o tom, co vlastně je třeba dělat, vymyslet a/nebo změnit, aby budování počítačových sítí přinášelo co možná největší efekt. Zkusme si tyto představy stručně nastínit - pomůže nám to lépe pochopit další vývoj v tak bouřlivě se měnící oblasti, jakou počítačové sítě bezesporu jsou.
Jako první a vcelku nejpřirozenější úkol vyvstala potřeba budování technických prostředků pro přenos dat mezi vzájemně propojenými počítači.
Zde je třeba si uvědomit, že se tak dělo v době, kdy přenosové technologie byly na mnohem nižší úrovni než dnes. Navíc byly tyto přenosové technologie zaměřeny především na potřeby přenosu lidského hlasu (obecně na přenos analogových signálů), a nikoli na přenosy dat, které mají digitální povahu. To, co bylo zapotřebí udělat, bylo vyvinout dokonalejší přenosové technologie, s vyššími přenosovými rychlostmi a s přijatelnými náklady, s menší poruchovostí a četností chyb, s větší provozní spolehlivostí, a uzpůsobit je potřebám přenosů dat. V době, kdy se s propojováním počítačů teprve začínalo, se pro datové přenosy nejčastěji používaly pevné telefonní okruhy nižších přenosových rychlostí (vesměs v řádu jednotek, maximálně desítek kilobitů za sekundu), osazené nezbytnými modemy. Teprve později se začaly používat i jiné, rychlejší přenosové technologie, schopné "dosáhnout" na větší vzdálenosti - mikrovlnné a družicové spoje apod. Postupně se ovšem zvyšovala i přenosová rychlost, dosažitelná na pevných telefonních okruzích, stále však ještě svou podstatou analogových. Ještě později se pak začaly objevovat i první skutečně digitální přenosové cesty.
Přenosové cesty a prostředky, využívané při propojování počítačů, obvykle spadaly po technické i legislativní stránce do kompetence příslušných spojových organizací, od kterých si je provozovatelé prvních počítačových sítí museli pronajímat. "Lidé od spojů" ovšem vždy měli (a stále mají) své vlastní představy o tom, jaké druhy datových přenosů jsou nejvhodnější - tyto jejich představy vychází především z tradice spojů jako takových, a jsou v některých významných aspektech odlišné od představ, ke kterým brzy dospěli "lidé od počítačových sítí". Některé z těchto "filosofických" rozdílů jsme si popisovali již v tématu týdne v CW 6/94, proto si jen stručně naznačme alespoň tu nejdůležitější odlišnost v přístupech obou táborů: "lidé od spojů" vychází z předpokladu, že komunikace mezi dvěma účastníky má i v počítačových sítích trvalejší charakter (což v telekomunikacích skutečně platí), a proto se snaží přidělovat jim přenosovou kapacitu trvale, formou tzv. přepojování okruhů (circuit switching). Naopak "lidé od počítačů" si brzy povšimli, že komunikace dvou účastníků má většinou spíše nárazový charakter, a že tudíž není přiliš rozumné přidělovat jim určitou přenosovou kapacitu jen k jejich výhradnímu použití. Místo toho považují za výhodnější ponechat veškerou přenosovou kapacitu pro společné využití, resp. umožnit její sdílení více účastníky, kteří spolu komunikují. K tomu ovšem bylo nutné nejprve vyvinout vhodnou přenosovou techniku - tzv. přepojování paketů (packet switching).
Nebylo to ovšem jen přepojování paketů - odlišnosti v pořebách telekomunikací a počítačových sítí si vynutily také vývoj dalších přesnosových technik, neboli konkrétních způsobů využití přenosových cest, které byly k dispozici.
Jako druhý zásadní úkol se ukázala potřeba sjednotit způsob, jakým jednotlivé počítače využívaly své vzájemné propojení - neboli způsob, jakým se počítače připojovaly k nově vznikajícím počítačovým sítím, a jakým v nich pracovaly.
Propojit dva počítače může v podstatě každý. Stejně tak si každý může vymyslet svůj vlastní způsob toho, jak spolu budou takovéto dva počítače komunikovat. Všechny další počítače, které pak mají být k takovéto zárodečné síti připojeny, pak ale nutně musí respektovat stejná "pravidla hry".
V obecném případě si vlastně kdokoli může vytvořit svou vlastní síťovou architekturu jakou ucelenou soustavu názorů na to, jak by měly být počítačové sítě budovány a jak by měly fungovat, doplněnou o konkrétní postupy a metody realizace těchto představ (komunikační protokoly). Problém je ovšem v tom, že když si to každý skutečně udělá zcela "podle svého", výsledkem budou vzájemně neslučitelné sítě.
Tendence dělat si vše po svém se zcela zákonitě objevily již na počátku budování "skutečných" počítačových sítí, překračujících experimentální rámec a směřujících naopak ke komerčnímu nasazení, a to nikoli překvapivě ze strany největších výrobců výpočetní techniky. Příkladem mohou být ryze proprietární (tj. vlastní, nestandadní) síťové architektury SNA (Systems Network Architecture) firmy IBM, či síťová architektura DNA (Digital Network Architecture firmy Digital Equpiment Corporation).
Naštěstí se ale i zde včas prosadil tlak uživatelů (i "rozum" mnoha výrobců), který vyústil v hledání a formování všeobecně uznávaných a dodržovaných standardů i na poli počítačových sítí. Hlavními hráči zde byli především různé standardizační a vědeckovýzkumné instituce, a nikoli konkrétní výrobci. V USA takto vznikla rodina protokolů TCP/IP (Transmission Control Protocol / Internet Protocol), na jejímž základě byla vybudována dnes již celosvětová síť Internet (které bude ještě letos věnováno samostatné Téma týdne). Mezinárodní organizace ISO (International Standards Organization, správně: International Organization for Standardization) zase dala vzniknout tzv. referenčnímu modelu ISO/OSI (Open Systems Interconnection Reference Model).
Se svou představou síťové architektury ovšem přišli i "lidé od spojů". Ti si totiž vcelku zákonitě uvědomili, že když si uživatelé budují své počítačové sítě sami, a od nich si pouze pronajímají "holé" přenosové cesty, přichází tak o významný zdroj zisků. Proto jejich standardizační organizace (CCITT, Comite Consultatif International de Telegraphique et Telephonique, neboli Mezinárodní poradní sbor pro telefonii a telegrafii) vytvořila vlastní síťovou architekturu X.25, byť zaměřenou jen na čistě přenosové funkce. Podle tohoto standardu jsou pak budovány tzv. veřejné datové sítě, jejichž služby spojové organizace poskytují na běžném komerčním základě. Také této problematice bude věnováno jedno z příštích Témat týdne.
Jako třetí zásadní úkol se ukázala potřeba odlehčit jednotlivým hostitelským počítačům sítě, a rozložit jejich individuální zátěže pokud možno rovnoměrně po celé síti.
Tento třetí požadavek je vlastně voláním po distribuovaných systémech, jejichž jednotlivé komponenty dokáží vzájemně spolupracovat natolik, že jejich skutečná individualita splyne, a navenek se budou jevit jako jediný celek, vybavený součtem svých individuálních zdrojů.
Tendence ke tvorbě distribuovaných systémů je vcelku přirozenou tendencí, která se objevuje v okamžiku, kdy je potřeba řešit nějaký opravdu rozsáhlý úkol, na který již nestačí jediný centrální výpočetní prvek. Znamená ovšem zásadní ústup od dosavadního, přísně centralizovaného výpočetního modelu host/terminál.
Ovšem v době, kdy se tato tendence ke tvorbě distribuovaných systémů začala plně projevovat, došlo v samotném "světě počítačů" doslova k revoluci - k nástupu osobních počítačů a "malé" výpočetní techniky obecně. No a tato revoluce způsobila velmi významné změny i ve "světě počítačových sítí": vytvořila nové motivace, které lidi vedou k propojování počítačů do počítačových sítí, a dala vniknout zcela novým kategoriím sítí. Způsobila mj. i to, že se počítačové sítě začaly rozdělovat na lokální a rozlehlé.
Velká počítačová revoluce
Střediskové počítače jsme v našem povídání opustili v době, kdy byly na vrcholu své slávy - kdy vybavené rozsáhlými terminálovými sítěmi a provozované v režimu sdílení času dokázaly sloužit i stovkám uživatelů současně.
Vývoj výpočetní techniky jako takové tím ale zdaleka neskončil. Pokroky na poli softwarových technologií umožnily realizovat dokonalejší víceuživatelské operační systémy, vymýšlet nové programovací jazyky a psát pro ně efektivní překladače, a zejména zavádět nové a nové druhy aplikací, které lidem dokázaly významně pomáhat při jejich práci. Snad nejzásadnější vliv na vývoj výpočetní techniky jako takové ale měly změny, ke kterým docházelo ve výrobních technologiích.
Jestliže pouhé procesory prvních počítačů, budované ještě s využitím elektronek, zabíraly celé místnosti, s nástupem tranzistorů bylo možné vtěsnat celý procesor do několika větších skříní. Když se pak objevily první integrované obvody, počet těchto skříní se začal zmenšovat, až se při určitém stupni integrace podařilo umístit celý procesor do jediné skříně. Stupeň integrace, neboli počet toho, co se výrobcům podaří "vtěsnat" na jednotku plochy křemíkového čipu, však nadále rostl závratným tempem, a tak se brzy podařilo umístit celý procesor na jedinou desku s integrovanými obvody. No a netrvalo dlouho, a celý procesor se vešel do jediného integrovaného obvodu - na světě byl první mikroprocesor. Stalo se tak v roce 1971, vyrobila jej firma Intel Corporation, byl 4-bitový, měl 2250 tranzistorů na čipu o ploše 1/6 x 1/8 palce, a jmenoval se "4004". Jeho výpočetní schopnosti se téměř vyrovnaly schopnostem legendárního počítače ENIAC z roku 1946, který ovšem vážil 30 tun, zabíral plochu 1000 čtverečních stop, měl 17648 elektronek, a jen pro jejich žhavení potřeboval menší elektrárnu. Inu, byl to opravdový pokrok.
První mikroprocesor sice ještě nezpůsobil žádný převrat, ale byl prvním krokem na cestě k mnohem výkonnějším a složitějším mikroprocesorům, kterým se již dostalo významného praktického využití - tak významného, že již udělaly onu příslovečnou "díru do světa".
Samotný mikroprocesor je ovšem jen pouhou konstrukční součástkou, která sama o sobě není vůbec schopná funkce. Doslova explozivní vývoj na poli polovodičových (i jiných) technologií však umožnil vyrábět v dostatečně malém provedení a za únosně nízkou cenu i veškeré ostatní komponenty, které jsou potřeba k vytvoření plnohodnotného počítače: paměti i nejrůznější systémové obvody (řadiče přerušení, budiče sběrnic, stykové obvody, řadiče periferních zařízení apod.).
Díky tomu pak bylo možné vyrobit takový počítač, který byl svými rozměry dostatečně malý na to, aby si jej mohl koncový uživatel postavit přímo na svůj stůl. Kromě toho však i jeho pořizovací cena mohla být tak malá, že již připadalo v úvahu, aby jej měl příslušný uživatel jen a jen pro sebe - tedy aby se o něj nemusel s kýmkoli dělit, mohl jej využívat tehdy, kdy se to právě jemu hodí, a v ostatní době jej mohl nechat zahálet.
No a právě tento moment způsobil doslovnou revoluci, avizovanou již v nadpisu tohoto odstavce - skutečný převrat nejen na poli technologických možností a funkčních schopností počítačů, ale především v přístupu člověka k výpočetní technice. Světlo světa spatřily počítače, které si skutečně zasloužily přívlastek "osobní"
Od minipočítačů k osobním počítačům
Přechod od střediskových počítačů k osobním počítačům samozřejmě nebyl skokový: velké střediskové počítače, sloužící celým velkým pracovním kolektivům, dostaly časem konkurenci v koncepčně téměř shodných, ale rozměrově menších a hlavně lacinějších minipočítačích. Ty se již vyplatilo přidělit menším kolektivům lidí - jestliže například původně sloužil jeden velký střediskový počítač všem zaměstnancům určité velké firmy, nyní již bylo myslitelné, aby si každé větší oddělení pořídilo vlastní minipočítač. Tento trend ke zmenšování počtu uživatelů, kteří se musí dělit o jeden společný počítač, pak díky pokrokům ve výrobních technologiích pokračoval rychle kupředu, až dosáhl svého absolutního cíle: možnosti přidělit samostatný počítač každému jednotlivému uživateli.
Ani nástup skutečně "osobních" počítačů však nebyl okamžitý. První počítače, určené jen pro jednoho uživatele, zase nebyly až tak laciné, aby je bylo možné přidělit skutečně všem jednotlivým uživatelům, kteří o to projevili zájem. Opravdu masové nasazení osobních počítačů se stalo možné až tehdy, když jejich cena dostatečně poklesla - což zase určitou dobu trvalo, než se prosadil jeden všeobecně uznávaný standard (osobní počítač IBM PC), jeho výroba dosáhla potřebných objemů, a zapracovalo také potřebné konkurenční prostředí.
Teprve pak se stalo skutečně možným, aby každý uživatel měl svůj vlastní počítač jen a jen pro sebe. Neznamenalo to ovšem, že střediskové počítače a minipočítače tím rázem zmizely ze scény - oba světy vedle sebe dlouhou dobu koexistovaly, a často spolu těsně spolupracovaly. Teprve v poslední době lze pozorovat systematické "vymírání" střediskových počítačů a minipočítačů.
Aplikace se stěhují ...
Možnost, aby každý uživatel měl svůj vlastní počítač jen a jen pro sebe, znamenala radikální odklon od původního, ryze centralistického modelu host/terminál, podle kterého byly provozovány všechny střediskové počítače a minipočítače. Nyní již nebylo třeba dbát na to, aby se existující výpočetní kapacita rovnoměrně rozdělila mezi všechny aktuální uživatele - nyní již bylo možné přidělit právě prováděné úloze celý počítač se všemi jeho zdroji.
Aplikace, dosud provozované výhradně na centrálních hostitelských počítačích a komunikující se svými uživateli prostřednictvím terminálových relací, se tak mohly přestěhovat přímo za svými uživateli, do jejich osobních počítačů, a celé je obsadit.
Z představy, že uživatelské aplikace mohou skutečně "obsadit" celý osobní počítač, vyšel i operační systém MS DOS, který se prosadil spolu s počítači IBM PC. Tento jednoduchý operační systém je jednouživatelský, a tudíž ani nepotřebuje znát pojem uživatele, nepotřebuje uvažovat, že by například různé soubory mohly mít své vlastníky, že by bylo třeba zavádět nějaká přístupová práva a z nich vyplývající omezení. Navíc je tento operační systém jednoúlohový, a předpokládá tedy, že uživatel nebude nikdy provozovat více jak jednu úlohu současně. Díky tomu vystačí s jediným "zabudovaným" terminálem, resp. s jedinou klávesnicí a s jediným monitorem, které ani za terminál nepovažuje - protože nepřipouští existenci jiných terminálů, resp. jiných dvojic klávesnice+terminál. Vzhledem k tomu operační systém MS DOS ani nezná pojem terminálové relace.
Pravdou je, že díky tomuto přístupu se velmi mnoho věcí značně zjednodušilo - například nebylo nutné zavádět žádné sdílení času či jiný mechanismus, umožňující současný běh více úloh, žádné ochranné mechanismy apod. Vzhledem k tomu pak mohl samotný MS DOS vyjít dostatečně jednoduchý a laciný.
Poměrně brzy se ale zjistilo, že předpoklad o provozování jen jediné úlohy je chybný, a pro většinu uživatelů značně omezující. Proto se teprve dodatečně do MS DOSu dostaly potřebné mechanismy, umožňující současný běh více úloh, neboli tzv. multitasking - vesměs ale formou nadstaveb nad samotným MS DOSem (nejvýznamnějším příkladem jsou v tomto směru MS Windows).
Od extrému k extrému ...
Přechod od přísně centralizovaných hostitelských počítačů k samostatným (izolovaným) osobním počítačům byl přechodem od jednoho extrému ke druhému. Byl motivován snahou pomoci koncovému uživateli - dát mu rozumnou výpočetní kapacitu jen a jen k jeho výhradnímu využití - ale zcela zákonitě sebou přinesl i některé záporné momenty. Tím nejvýznamnějším zřejmě byla skutečnost, že nyní se každý uživatel musel o svůj počítač starat sám: sám si instalovat nové programy, sám si k počítači připojovat periferní zařízení a instalovat k nim příslušné ovladače, sám si udržovat pořádek ve svém "souborovém hospodářství", zálohovat si své soubory apod. Nebo musel mít k ruce někoho, kdo by to dělal za něj. Původní potřeba udržování (tzv. správy) jednoho centrálního počítače, kterou mohli mít na starosti k tomu určení specialisté, se tak změnila na nutnost správy mnoha malých samostatných počítačů - což ale není ve větším měřítku příliš schůdné (jak jsme si již naznačovali v tématu týdne v CW 8/94).
Také nejrůznější systémové zdroje (aplikace, datové soubory, tiskárny apod.) musely být mnohonásobně zduplikovány, tak aby je měli k dispozici všichni uživatelé, kteří o ně projevili zájem. Ne vždy to ovšem bylo cenově i jinak únosné, protože například cena skutečně kvalitních laserových tiskáren ještě zdaleka neklesla natolik, aby je každý uživatel mohl mít jen a jen pro sebe.
Proto se zcela zákonitě musely objevit opětné tendence k centralizaci. Nikoli ovšem k centralizaci výpočetní kapacity, která se mezitím stala opravdu velmi lacinou, jako spíše snahy o centralizaci v oblasti správy - aby stačilo "udržovat pořádek" na jednom místě, než na mnoha místech současně. Dalším důvodem byla možnost sdílení centrálně umístěných zdrojů, které stále ještě nebylo možné přidělit jednotlivým koncovým uživatelům k výhradnímu využívání.
Vedle spíše ekonomických a organizačních aspektů se však objevily i mnohé další, ryze praktické důvody pro zpětnou centralizaci. Tyto důvody přitom souvisí s tím, k čemu se vlastně výpočetní technika používá. Jestliže první počítače sloužily převážně vědeckotechnickým výpočtům, které si zpracovávali jednotliví uživatelé sami za sebe, s postupem času se na počítačích začaly ve stále větší míře provozovat i takové aplikace, které vyžadují spolupráci či součinnost více uživatelů. Takovéto aplikace pak není dost dobře možné provozovat na vzájemně izolovaných počítačích, bez možnosti vzájemného sdílení potřebných dat. Ani nespřažený (off-line) přenos dat, realizovaný například po disketách, zde není příliš vhodný, protože je značně pomalý, a navíc závislý na lidském činiteli (který není zdaleka neomylný). V mnohých případech se proto ukázalo jako nezbytné, aby určité aplikace sdílely jediný, centrálně umístěný a centrálně udržovaný (například centrálně zálohovaný) exemplář svých dat.
Osobní počítače v roli terminálů
Jednou z forem koexistence zpočátku striktně individualistického "světa osobních počítačů" a přísně centralizovaného "světa střediskových počítačů", která současně vycházela vstříc potřebám opětné centralizace, bylo vzájemné propojování osobních a střediskových počítačů.
Bezprostředním důvodem pro takovéto propojování byla skutečnost, že ani s masovým nasazením osobních počítačů nedošlo k převodu všech běžně provozovaných aplikací z centrálních střediskových počítačů na počítače osobní. Právě naopak - skutečnost byla spíše taková, že nové aplikace se již zaváděly na osobní počítače, ale ty staré se stále provozovaly "po staru", na centrálních střediskových počítačích, a předpokládaly použití modelu host/terminál. Převod již existujících aplikací do nového prostředí totiž obvykle vyžadoval jejich úplné přepracování, což nebylo zadarmo a zcela bez problémů.
Co ale měl dělat uživatel, který potřeboval pracovat jak s aplikacemi na svém osobním počítači, tak i s aplikacemi, provozovanými stále ještě na centrálním počítači? Jistě, mohl si vedle osobního počítače postavit na svůj stůl ještě i terminál.
Naštěstí ale takovéto řešení nebylo jedinou možností. Pokud byl totiž osobní počítač se střediskovým vhodně propojen, bylo možné dosáhnout toho, aby vystupoval v roli jeho terminálu. Tedy aby napodoboval chování skutečného jednoúčelového terminálu (tzv. jej emuloval), a svému uživateli tak dával stejné možnosti, jako terminál skutečný. Toto řešení s tzv. emulací terminálu na osobním počítači mělo tu obrovskou výhodu, že bylo řešením "na žádost": uživatelův osobní počítač mohl v roli emulovaného terminálu vystupovat tehdy, kdy to bylo skutečně zapotřebí, a v ostatní době byl plnohodnotným osobním počítačem. Bylo to možné proto, že jeho vystupování v roli emulovaného terminálu bylo zajišťováno aplikačním programem, který si uživatel spouštěl až na základě skutečné potřeby.
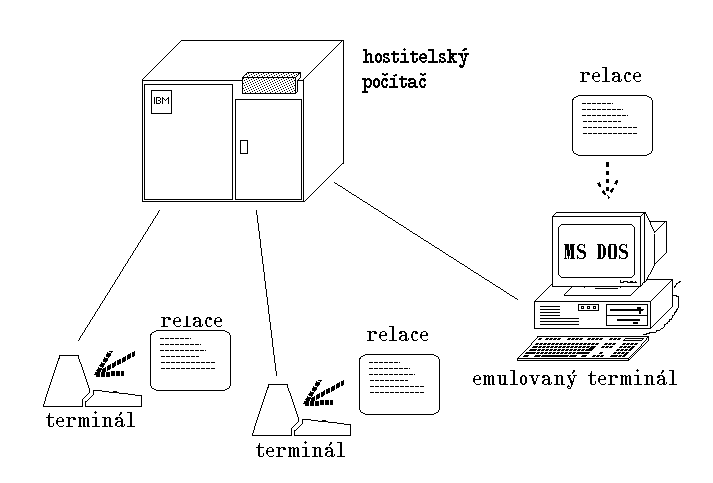 Obr. 9. Emulované terminály vs. "skutečné" terminály
Obr. 9. Emulované terminály vs. "skutečné" terminály
Osobní počítače byly ke střediskovým počítačům zpočátku připojovány obdobným způsobem, jako terminály skutečné - tedy prostřednictvím dvoubodových spojů (přes případné terminálové a komunikační řadiče). Teprve později, s nástupem lokálních sítí, došlo k určité změně ve způsobu připojování osobních počítačů ke střediskovým. Na způsobu jejich využití (v roli emulovaných terminálů) to ale nic nezměnilo.
Potřeba transparentního sdílení
Možnost emulace terminálů na osobních počítačích, a v důsledku toho možnost zřizovat z osobních počítačů terminálové relace s hostitelskými počítači, vycházela vstříc potřebě střídavého provozování aplikací jak na centrálních hostitelských počítačích, tak i na počítačích osobních. Nic však nedělala pro potřeby "nových" aplikací, vytvářených již pro osobní počítače, které ke svému fungování vyžadovaly sdílení určitých systémových zdrojů - souborů, periferních zařízení apod., nebo jim takovéto centrální umístění různých zdrojů alespoň značně prospívalo.
Určitá možnost zde sice byla: osobní počítače, připojené ke střediskovým, mohly mít určitý druh přístupu k systémovým zdrojům střediskových počítačů. Například bylo možné, pomocí vhodného přenosového programu (například programu KERMIT) přenést dávkovým způsobem určitý soubor ze střediskového počítače na osobní či naopak. Problém byl ovšem v rychlosti, která byla determinována způsobem připojení osobního počítače, dimenzovaným pro potřeby připojování terminálů, a dále v samotné podstatě takovéhoto přenosu, který byl pro uživatele viditelný (neboli: nebyl pro něj neviditelný, též: transparentní). Uživatel, resp. jím provozovaná aplikace, si museli plně uvědomovat, že příslušný objekt (systémový zdroj) se nachází někde jinde, a museli explicitně podniknout určité akce k tomu, aby jej získali (např. aby si jej jako soubor přenesli k sobě apod.).
Pro nově vytvářené aplikace bylo naopak mnohem výhodnější, aby způsob sdílení nejrůznějších centrálně umístěných zdrojů byl plně transparentní. Tedy aby mohli používat sdílené objekty, ale nemuseli si jejich sdílený charakter vůbec uvědomovat - především proto, aby je nemuseli rozlišovat od "vlastních", nesdílených objektů, a mohli s nimi pracovat přesně stejným způsobem. Tím se totiž mnoho věcí značně zjednodušilo.
Uvažujme jako příklad sdílení souborů, umístěných na nějakém centrálním počítači. Netransparentní přístup určitého počítače k těmto souborům je založen na tom, že pro tento počítač (a jeho uživatele) existuje principiální rozdíl mezi jeho "místními" soubory a soubory "vzdálenými" (které jsou sdíleny a nachází se na centrálním místě). Potřebuje-li uživatel takovéhoto počítače (resp. jím provozovaná aplikace) pracovat s některým "vzdáleným" souborem, pak tak činí jiným způsobem, než v případě místních souborů - například se musí sám explicitně postarat o jejich přenos z místa kde se nachází na místo, kde budou zpracovány, a pak zase o jejich navrácení. Naopak plně transparentní přístup ke sdílení souborů je takový, při kterém rozdíl mezi místním a vzdáleným souborem zcela mizí (přestává být patrný, resp. stává se plně transparentní), a s oběma druhy souborů se pracuje naprosto stejně (tj. o veškeré přenosy souborů či jejich částí se musí postarat mechanismy, které transparentní přístup ke sdíleným souborům zajišťují, a to bez "vědomí" toho, kdo se souborem pracuje).
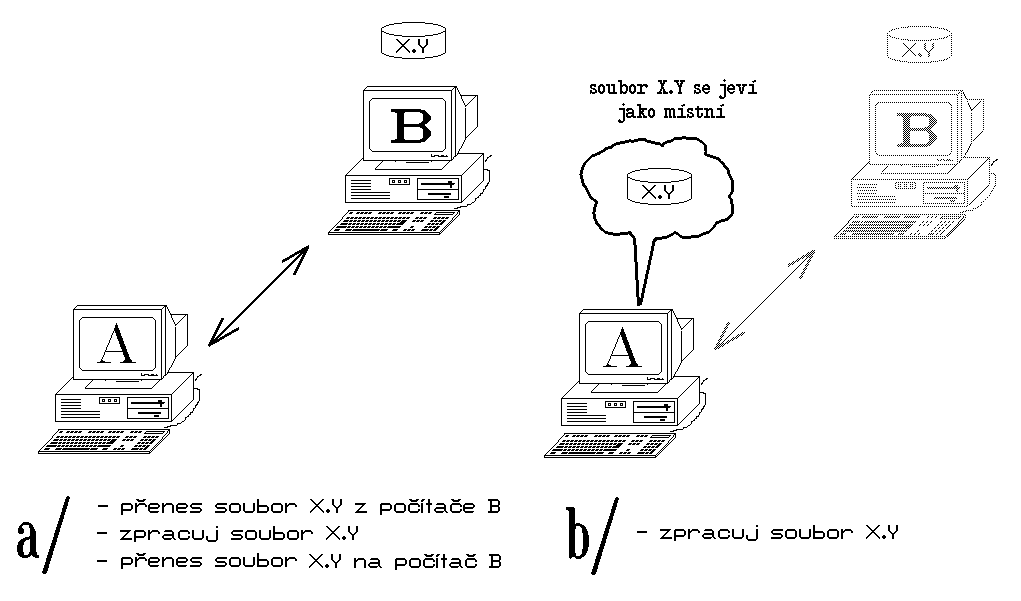 Obr. 10: Představa přístupu ke sdíleným souborům
a/ netransparentní b/ transparentní
Obr. 10: Představa přístupu ke sdíleným souborům
a/ netransparentní b/ transparentní
Problém ovšem byl, jak takovéto plně transparentní sdílení realizovat - nejen pro nejrůznější soubory, ale například i pro tiskárny, plottery, snímače, faxy apod.
Samozřejmě, bylo možné to naučit stávající střediskové počítače. Systémové zdroje, které za tímto účelem mohly nabídnout, byly často vcelku dostatečné. Znamenalo to ovšem vyvinout zcela nový druh systémových programů, které by takovéto plně transparentní sdílení podprovaly. No a v době, kdy všichni byli přímo fascinováni možnostmi "malé" výpočetní techniky, se nikomu do takovéto práce příliš nechtělo.
Volba tedy padla jednoznačně na "malé" počítače.
Pokroky v přenosových technologiích
Praktická realizace plně transparentního sdílení, zvláště pak sdílení souborů, vyžaduje velmi rychlou odezvu - jinak by totiž existoval markantní rozdíl v době přístupu k místním a vzdáleným souborům, což by znemožňovalo jejich vzájemné "splynutí" (alespoň z pohledu uživatele). Ovšem dostatečně rychlá odezva zase vyžadovala dostatečně rychlý přenosový kanál mezi příslušnými počítači.
Doposud používané techniky přenosu - zejména sériový přenos dle standardu RS-232-C, používaný pro připojování terminálů - byly pro tyto účely zcela nedostačující. Naštěstí se mezitím na obzoru objevily nové přenosové technologie, umožňující dosáhnout na krátké vzdálenosti (řádově desítky až stovky metrů) úctyhodné přenosové rychlosti v řádu megabitů za sekundu.
Historicky první byla přenosová technologie ARCNET (Attaches Resources Computing NETwork), se kterou přišla firma Datapoint Corporation již v roce 1977. Dosahovala přenosové rychlosti 2,5 megabitu, byla vcelku úspěšná, ale zůstala vždy proprietárním řešením, bránícím se oficiální standardizaci. Šanci proto dostal konkurenční Ethernet, který svou dnešní podobu získal v letech 1980 a 1982, a který se na rozdíl od ARCNETu plně "otevřel" formální standardizaci (v rámci sdružení IEEE, která jej vydala jako standard IEEE 802.3). Se svou přenosovou rychlostí 10 megabitů za sekundu a relativně nízkými náklady na zřízení přenosových cest a související techniku pak Ethernet zvítězil na celé čáře.
Jeho dominantní postavení příliš neohrozil ani další hráč, který se mezitím objevil na scéně - technologie Token Ring, vyvinutá firmou IBM a pracující s přenosovou rychlostí 4 megabity za sekundu (v novější verzi 16 Mbps).
Model klient/server
Jakmile byly k dispozici dostatečně rychlé přenosové cesty, cesta k realizaci plně transparentního sdílení se začala otevírat. Nejprve ale bylo třeba vymyslet celkovou strategii, či spíše model, který by určoval vzájemné vztahy a postavení počítačů, které se sdílení účastní.
Po počátečním hledání nejvhodnějšího modelu se ukázalo jako výhodné implementovat sdílení tak, aby všechny zúčastněné strany měly maximální možnou míru autonomie a nezávislosti na sobě. V praxi to znamenalo řešit sdílení formou poskytovaní služeb. Zde totiž vystupují dva subjekty - poskytovatel služby (ten, kdo něco nabízí), a uživatel služby (tj. ten, kdo o něco žádá) - kterým stačí stanovit způsob jejich vzájemné komunikace (tedy způsob žádání o konkrétní služby a formu reakce na tyto žádosti), ale není již nutné jim mluvit do toho, jak si implementaci příslušných služeb zajistí, resp. proč budou o služby žádat a k čemu jejich výsledky využijí. V konkrétním případě sdílení souborů je poskytovatelem služby ten, u koho se soubor nachází (tj. kdo jej má uložen na svém disku). Žadatelem je pak ten, kdo s takovýmto souborem chce pracovat, a kdo si v rámci své žádosti "řekne" o soubor jako celek či jeho část.
Začaly se tedy od sebe oddělovat subjekty, které služby poskytují - tzv. servery, a subjekty, které je využívají - těm se pak říká klienti. Charakteristickým je pro jejich vztah to, že veškerá aktivita je vždy očekávána od klienta, zatímco server své služby nikomu nevnucuje a pouze pasivně čeká, až bude o jejich poskytnutí klientem explicitně požádán. Významné je pak i to, že jeden server může poskytovat své služby více klientům, ať již současně či postupně. Vztah mezi klientem a serverem tedy není přísným vztahem 1:1, ale obecně vztahem 1:n.
Myšlenka oddělit poskytovatele od uživatele služby samozřejmě není specialitou počítačových sítí. Je mnohem obecnějším principem, obvykle označovaným jako model (architektura) model klient/server, a své uplatnění nachází v mnoha dalších oblastech, které nejsou nutně distribuovány či vázány na prostředí počítačových sítí - například v nejrůznějších databázích. V oblasti počítačových sítí je model klient/server obvykle implementován tak, že některé počítače vystupují v roli serverů, a jiné v roli klientů, i když není vyloučeno ani to, aby jeden a tentýž počítač vystupoval současně v obou rolích. V roli klientů vesměs vystupují ty počítače, na kterých pracují jednotliví uživatelé - proto se těmto počítačům také říká pracovní stanice. Uživatelé, kteří na pracovních stanicích pracují, resp. jimi provozované aplikace, jsou pak konečnými konzumenty poskytovaných služeb. Podobně mohou i v roli serverů vystupovat takové počítače, na kterých uživatelé pracují, resp. takové, které kromě své role serverů plní ještě i jiné úkoly. Pak jde o tzv. nededikované (též: nevyhrazené) servery. Z hlediska výkonnosti, ale především z hlediska celkové spolehlivosti je ale výhodnější, když příslušný počítač se věnuje výhradně svému fungování v roli serveru, a vedle toho již nedělá nic jiného. Pak již jde o tzv. dedikovaný (též: vyhrazený) server. V jeho prospěch hovoří ještě i to, že může být pro svou funkci předem optimalizován, například vybaven větším objemem operační paměti či disku na úkor výkonné grafické karty a barevného monitoru. Druhy serverů a jejich služby
Služby, které poskytují servery dnešních počítačových sítí, jsou velmi různorodé, a podle nich jsou pak také rozlišovány různé druhy serverů. Zřejmě nejrozšířenější jsou takové servery, které svým klientům poskytují jako službu uchovávání jejich souborů - pak jde o tzv. file servery (též: souborové servery). Klientem file serveru může být jak počítač, vybavený vlastním diskem, tak i tzv. bezdisková stanice, která vlastní disk vůbec nemá. Hlavní výhody, které uchovávání souborů na file serveru místo na lokálním disku přináší, spočívají jednak ve zvýšení využitelné diskové kapacity, a jednak v možnosti sdílení souborů - například jeden jediný exemplář určité aplikace, umístěný na file serveru ve formě sdíleného souboru, je v principu dostupný více uživatelům současně. Další výhodou je i centralizované umístění takových souborů, které mají privátní povahu (v tom smyslu, že se nepředpokládá jejich sdílení), neboť je lze centrálně zálohovat, centrálně testovat na přítomnost virů apod. Nevýhodou uchovávání souborů na file serverech je pak přeci jen nezanedbatelná režie, spojená s jejich přenosem mezi serverem a pracovní stanicí v roli klienta.
Pro správné pochopení významu a funkce file serveru je dobré si uvědomit, že komunikace mezi file serverem a klientem je na úrovni požadavků typu: chci číst soubor XY, a odpovědí typu: zde je obsah souboru XY. O tom, v jakém tvaru a jakým způsobem si server svěřené soubory uchovává, si rozhoduje jen on sám. Díky tomu je například možné, aby počítače v roli klienta i serveru stály na různých platformách - například aby klient byl počítačem s operačním systémem MS DOS, zatímco server byl Unixovským počítačem. Podstatné pro možnost jejich spolupráce je to, aby se shodli na způsobu vzájemné komunikace, tedy na formě žádostí o služby a na reakcích na tyto žádosti.
Předchůdcem dnešních file serverů byly tzv. diskové servery, které jako svou službu nabízely části svých disků. Komunikace mezi souborovým serverem a jeho klientem probíhala na úrovni požadavků typu: načti (zapiš) obsah sektoru XYZ, resp. odpovědí typu: zde je obsah sektoru XYZ. U souborových serverů si pak konkrétní organizaci souborů na disku (tj. konkrétní způsob jejich uložení) zajištoval podle svých potřeb klient sám, zatímco u file serveru si toto zajišťuje server.
Další velmi rozšířenou kategorií serverů jsou tzv. print servery (neboli: tiskové servery), které jako svou službu poskytují tisk na "svých" tiskárnách (míněno: na tiskárnách, připojených k těmto print serverům). Na rozdíl od file serverů, jejichž služby mají obvykle interaktivní charakter, je mechanismus fungování print serverů vysloveně dávkový - klient sestaví data, která chce vytisknout, do tzv. tiskové úlohy (což je zvláští druh dávky), a pošle jej print serveru. Ten zařadí tiskovou úlohu do fronty tiskových úloh, které čekají na tisk na příslušné tiskárně, a zde pak úloha čeká, dokud na ni nedojde řada a není skutečně vytisknuta. Print servery jsou tedy ve své podstatě prostředky, které umožňují více uživatelům sdílet jednu a tutéž periferii - tiskárnu. Zde je dobré si ještě jednou zdůraznit, že server je role, resp. postavení, a nikoli "něco". Funkci print serveru může například vykonávat program, běžící na počítači, který jinak vystupuje v roli file serveru (tj. vedle tohoto programu zde běží ještě jiný program resp. úloha, která vykonává funkci file serveru). Stejně tak je ale možné, aby i print server byl dedikovaný, tj. aby šlo o počítač, který plní právě a pouze funkci print serveru, nebo aby funkci print serveru vykonávala například pracovní stanice některého z uživatelů.
Mezi další druhy serverů, které slouží potřebám sdílení různých periferních zařízení, patří například modemové servery, faxové servery, CD ROM servery apod. Zajímavou kategorií jsou tzv. přístupové servery (access servers). Jejich úkolem je umožnit vstup do sítě a práci v ní i takovým uživatelům, jejichž počítače nejsou součástí sítě. Mohou to být například počítače, které mají uživatelé u sebe doma, přes veřejnou telefonní síť a modem se z nich napojí na přístupový server, a jeho prostřednictvím se pak dostávají do stejného postavení, jako kdyby pracovali přímo na některém uzlovém počítači dané sítě. Služby, poskytované servery, nemusí nutně mít povahu sdílení technických prostředků - ostatně již file server je názorným příkladem serveru, který nabízí sdílení objektů programového, resp. datového charakteru. Kromě něj pak mohou existovat ještě další druhy serverů, které umožňují sdílet jinak uspořádaná data, než ve formě souborů - například různé databázové servery. Ještě obecnější jsou pak různé druhy informačních serverů, které jsou dnes nezbytné i pro samotný chod sítí jako takových. Například servery jmen (name servers), které dokáží odpovědět na dotaz, jakou síťovou adresu má uzel s takovou a takovou symbolickou adresou, nebo identifikační servery (authentication servers), které ověřují pravost jmen a hesel uživatelů, kteří se přihlašují do sítě. Vedle všech těchto serverů, které lze s jistým zjednodušením označit za "systémové", mohou v roli poskytovatelů služeb vystupovat i nejrůznější aplikace, které si uživatelé sami vytvoří, nechají vyvinout na zakázku či zakoupí jako běžné komerční produkty. Tyto aplikace pro síťové prostředí pak provozují na počítačích, které se označují jako aplikační servery.
Sítě serverového typu a sítě peer-to-peer
Počítačové sítě, které jsme si až doposud popisovali a které vychází z modelu klient/server, jsou dnes stále častěji označovány neformálně jako sítě serverového typu. To proto, že v nich existuje velmi ostrá hranice mezi počítači v rolích klientů a serverů - některé počítače jsou servery (a nejčastěji dedikovanými, tj. jsou vyhrazené jen tomuto svému úkolu), zatímco ostatní vůči nim vystupují v roli klientů (a jsou obvykle pracovními stanicemi uživatelů). Jinými slovy: některé počítače se vyhradí k tomu, aby sloužily jako servery, a ostatní slouží jako pracovní stanice uživatelů.
Takováto strategie však není vždy a všude optimální. Zvláště ve velmi malých sítích totiž nemusí být únosné (hlavně z ekonomických důvodů) vyhradit jeden, či dokonce několik počítačů jen pro roli serverů, a zakoupit pro ně poměrně drahý síťový software. Záleží to samozřejmě také na způsobu, jakým bude síť používána - pokud budou její síťové funkce využívány spíše jen příležitostně (například pro elektronickou poštu či občasné tisky na tiskárnách), pak může být mnohem výhodnější řešení, které v současné době nabízí tzv. sítě typu peer-to-peer.
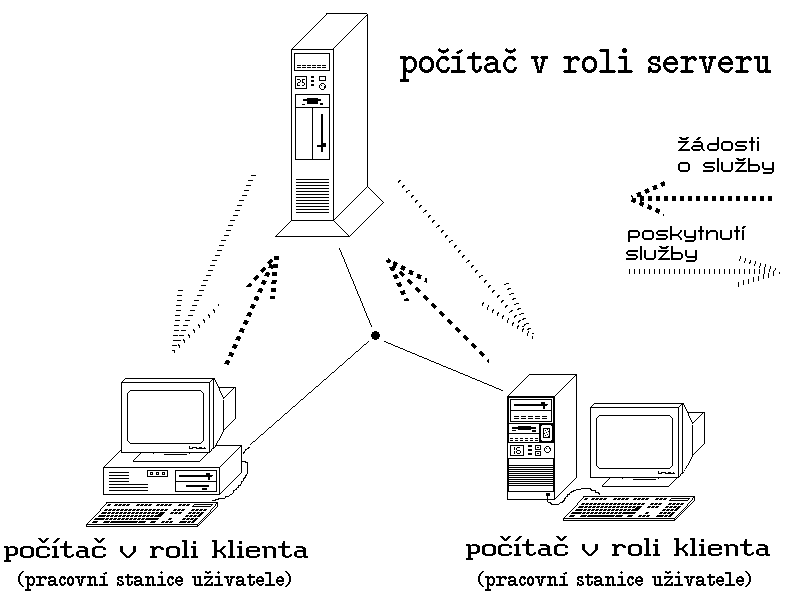 Obr. 11: Představa sítě serverového typu
Obr. 11: Představa sítě serverového typu
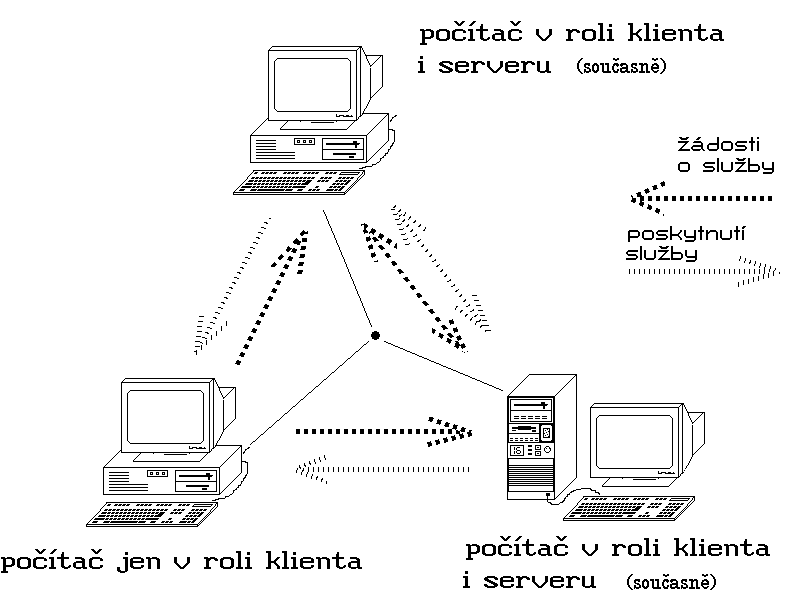 Obr. 12: Představa sítě typu peer-to-peer
Obr. 12: Představa sítě typu peer-to-peer
Základní charakteristikou těchto sítí je to, že již tak důsledně netrvají na oddělení serverů od klientů. Naopak přímo počítají s tím, že jednotlivé uzlové počítače mohou vystupovat v roli serverů a klientů současně, a této možnosti se snaží vycházet vstříc. Jejich filozofie předpokládá, že každý jednotlivý uživatel nabízí ostatním něco ze systémových prostředků a zdrojů svého počítače (především souborů, ale také např. tiskáren apod.), a sám využívá něco z toho, co mu stejným způsobem nabízí jiní. Počítače jednotlivých uživatelů pak vystupují v roli serverů (aby mohly nabídnout k využití to, co se uživatel daného počítače rozhodl zpřístupnit ostatním), a současně i v roli klientů, aby mu zpřístupnili to, co nabízí jiní.
Dalším charakteristickým rysem sítí peer-to-peer je jejich relativní jednoduchost oproti sítím serverového typu (projevující se např. omezeným repertoárem služeb a dalších souvisejících funkcí, jako např. zabezpečovacích mechanismů apod.). Na druhé straně zase mohou být výrazně lacinější. Další významnou charakteristikou sítí peer-to-peer je i to, že jsou vesměs koncipovány jen pro malý počet uzlů, například jen 20 či 30. Samotný název "peer-to-peer" v doslovném překladu znamená "rovný s rovným", což má zdůraznit rovnoprávné postavení jednotlivých uzlů jako protiváhu jejich striktního dělení na servery a klienty (resp. pracovní stanice).
Z hlediska celkové koncepce je ovšem třeba zdůraznit, že sítě typu peer-to-peer nejsou protipólem sítí na bázi modelu klient/server, protože samy z tohoto modelu vychází také. Spíše bychom je měli považovat za alternativu k sítím serverového typu (tj. k těm, ve kterých není role serveru kombinována s rolí klienta), a to ještě za alternativu z hlediska ceny, předpokládaného nasazení (ve velmi malých sítích, zatímco sítě serverového typu mohou být relativně velké), způsobu využití (spíše příležitostného, oproti intenzivnějšímu u serverových sítí), a v neposlední řadě i z pohledu nároků na uživatele - sítě typu peer-to-peer jsou zcela záměrně řešeny tak, aby si jejich instalaci a správu dokázali zajistit přímo koncoví uživatelé, zatímco u sítí serverového typu se přeci jen očekává účast specialistů.
Rozdíl mezi sítěmi serverového typu a sítěmi peer-to-peer se však stává stále více neurčitým. Serverové sítě se stávají lacinějšími, existují i ve verzích pro velmi malé sítě, a jejich instalace a správa je čím dál tím jednodušší. Na druhé straně schopnosti peer-to-peer sítí se stále více přibližují schopnostem serverových sítí, a roste i počet uzlů, které v těchto sítích mohou pracovat. Mizí i jediné kritérium, které by bylo možné považovat za jednoznačně určující - totiž použití dedikovaných serverů. Dnešní sítě peer-to-peer totiž také umožňují vyhradit některé uzlové počítače pro roli serveru, a znemožnit jejich současné využití jako pracovní stanice (tj. umožňují učinit z nich dedikované servery).
Do budoucna lze očekávat, že obě kategorie nejspíše splynou. Dnes však mezi nimi stále ještě existuje výrazná hranice. Spíše než svými užitnými vlastnostmi je ale dána cenou a způsobem marketingu příslušných síťových produktů. Typickým příkladem sítí serverového typu jsou dnes sítě NetWare firmy Novell, zatímco nejtypičtějšími představiteli peer-to-peer sítí jsou sítě LANtastic firmy Artisoft a Netware Lite firmy Novell.
Není LAN jako WAN! (?)
Počítačové sítě se dnes s oblibou rozdělují na lokální (též: sítě LAN, od anglického Local Area Network) a rozlehlé (též: sítě WAN, od Wide Area Network). Někdy se pak objevuje ještě i třetí kategorie, a to sítě metropolitní (sítě MAN, Metropolitan Area Network). Co si ale pod těmito pojmy přesně představovat? Jakmile se budeme chtít pokusit o přesnější definici, narazíme na zajímavý problém - kritérií a charakteristik, které se k vymezení lokálních a rozlehlých sítí přímo nabízí, je celá řada. Žádné z nich ale není absolutní, v tom smyslu, že by dokázalo dát vždy a za všech okolností odpověď na otázku, zda konkrétní síť je lokální či rozlehlá (případně metropolitní). Je proto třeba uvažovat celou řadu rozlišujících kritérií a počítat s tím, že jejich verdikty nemusí být jednoznačné, a že si mohou navzájem protiřečit. Vždy totiž budou existovat takové sítě, které budou ležet někde na pomezí, a jejichž zařazení do jedné či druhé (případně třetí) kategorie bude spíše otázkou subjektivního rozhodování. Na druhé straně ale budou vždy existovat i takové druhy sítí, o jejichž zařazení nebude pochyb, a které bude možné považovat za typické představitele jednotlivých kategorií. Jaká tedy mohou být rozlišující kritéria pro lokální, rozlehlé a metropolitní sítě? Jedno kritérium nabízí již samotný název: lokální zřejmě budou takové sítě, které se rozkládají na malé ploše, a rozlehlé takové, které se rozkládají na velké ploše. Jestliže se tedy nějaká síť rozpostírá po více kontinentech, jde zřejmě o síť rozlehlou. Naopak síť, propojující osobní počítače v rámci jediné místnosti, bude typickým příkladem sítě lokální. Kde ale leží hranice mezi nimi? Co například taková síť, která propojuje uzlové počítače v rámci celého města? Zde si ještě můžeme pomoci kategorií metropolitních sítí, ale v obecném případě tím jen z jednoho problému vyrobíme dva: kde je hranice mezi lokální a metropolitní sítí, a kde mezi metropolitní a rozlehlou sítí? Navíc zde vstupují do hry i možnosti novodobých přenosových technologií, které nejen zvětšují dosah typických lokálních sítí, ale hlavně je umožňují vzájemně propojovat i na velké vzdálenosti. Jestliže například propojíme mezi sebou dvě typické lokální sítě, které se nachází na různých kontinentech, jde pořád jen o dvě samostatné sítě, nebo tím vznikla jediná výsledná síť? A je to síť lokální, nebo rozlehlá? Spíše než na vzdálenosti pak může odpověď záviset na přenosové kapacitě a způsobu propojení, i na jeho celkovém systémovém řešení - tedy na tom, jak se vůči uživateli jednoho uzlového počítače "tváří" ostatní uzly, zda pro něj existují nějaké principiální rozdíly v přístupu k ostatním uzlům podle toho, kde se tyto uzly nachází, jaký charakter mají služby takovéto sítě apod. S kritériem fyzických vzdáleností úzce souvisí další kritérium, a to přenosová kapacita, resp. propustnost přenosových cest mezi jednotlivými uzly. Jak jsme si již podrobněji rozvedli v Tématu týdne v CW 8/94, platí zde nepřímá úměrnost - čím větší vzdálenost, tím menší je dosažitelná přenosová kapacita. V současné době opravdu existuje výrazný odstup v přenosových rychlostech sítí, které jsou typickými představiteli obou hlavních kategorií - lokální sítě dnes pracují s přenosovými rychlostmi v řádu desítek megabitů za sekundu (konkrétně: sítě typu Ethernet s přenosovou rychlostí 10 MBitů za sekundu, sítě Token Ring 4 či 16 MBitů, a sítě na bázi FDDI s přenosovou rychlostí 100 Mbitů), zatímco u sítí rozlehlých jde o rychlosti řádově nižší - kupř. celá Česká republika je připojena k celosvětové síti Internet linkou 64 KBit za sekundu, a například síťě EUNET či FIDO vystačí s ještě nižší přenosovou rychlostí, kterou musí "vyždímat" z veřejné telefonní sítě (nejčastěji 9,6 či 14,4 KBitů za sekundu, podle použitých modemů). Ve světě však dosahují rozlehlé sítě přenosových rychlostí až v řádu jednotek megabitů za sekundu. Je to sice stále o řád méně, než "nejpomalejší" lokální sítě, ale díky rychlému vývoji moderních technologií se tento rozdíl neustále zmenšuje. Do budoucna proto nelze s kritériem používané přenosové rychlosti příliš počítat. Dalším markantním rozdílem mezi lokálními a rozlehlými sítěmi je vztah jejich provozovatelů k používaným přenosovým cestám. Zde je dobré si nejprve uvědomit, že snad každý stát světa nějakým způsobem reguluje, kdo a jak smí budovat přenosové cesty na veřejných prostranstvích. Až na čestné výjimky (např. v USA) má na tuto činnost ze zákona monopol jediná organizace - nejčastěji správa spojů či obdobná instituce příslušného státu. Pro provozovatele počítačových sítí to pak znamená, že pokud si chtějí budovat vlastní přenosové cesty, mohou tak činit pouze v rámci budov, které vlastní, případně v rámci celých areálů, jejichž pozemky jsou jejich majetkem - například v rámci univerzitních areálů (tzv. kampusů). Jakmile se ale dostanou až na veřejná prostranství, musí respektovat existenci příslušného monopolu. Pokud potřebují například jen překlenout nějakou veřejnou komunikaci, aby mohli propojit dvě své budovy, mohou vystačit s povolením od k tomu oprávněné organizace. Když ale potřebují zřídit propojení na větší vzdálenosti (například mezi dvěma městy), jsou nuceni si pronajmout potřebné přenosové cesty od organizace, která má na jejich budování a provozování monopol. U typických lokálních sítí jsou tedy jejich provozovatelé současně i majiteli přenosových cest (kabelových rozvodů), zatímco u typických rozlehlých sítí je majitelem použitých přenosových cest příslušná spojová organizace, a provozovatelé sítě si je pouze pronajímají.
Dosti výrazným rozdílem mezi lokálními a rozlehlými sítěmi mohou být služby, které jsou v těchto sítích nejčastěji využívány. Například s elektronickou poštou se můžeme setkat zhruba ve stejné míře u obou druhů sítí sítí. S přenosem souborů pak více u sítí rozlehlých, zatímco v lokálních sítích převažuje spíše sdílení souborů (tj. plně transparentní přístup k souborům, které se ve skutečnosti nachází na jiném počítači, a nikoli netransparentní přenos souborů, explicitně iniciovaný uživatelem). Sdílení některých periferií (například tiskáren) je téměř výhradní záležitostí sítí lokálních, zatímco u jiného hardwaru (například specializovaných maticových procesorů) může jít spíše o doménu rozlehlých sítí. Vzdálené přihlašování se používá v obou druzích sítí, ovšem k poněkud jiným účelům - u lokálních sítí nejčastěji jako způsob dálkového ovládání vzdáleného počítače (ke kterému správce sítě nemusí utíkat po schodech o celé patro výš, aby na něm provedl nějaký drobný úkon), zatímco u rozlehlých sítí jde spíše o prostředek ke sdílení jiných zdrojů, zejména výpočetní kapacity (takto lze například z Prahy pracovat na superpočítači někde v USA, pokud na to uživatel má potřebná přístupová práva).
Další rozdíl mezi lokálními a rozlehlými sítěmi by bylo možné hledat v tom, jaké počítače jsou do nich zapojovány v roli uzlových počítačů. Rozlehlé sítě, které jsou historicky starší, vznikaly jako vzájemné propojení "velkých" počítačů - tedy střediskových počítačů a minipočítačů - které jsou mimo jiné charakteristické tím, že jsou provozovány trvale a slouží více uživatelům. Naproti tomu historicky mladší lokální sítě propojují spíše "malé" počítače, které jsou osobními počítači jednotlivých uživatelů, a jsou v provozu pouze v době, kdy je jejich uživatelé skutečně potřebují (což ovšem neplatí pro servery lokálních sítí, které bývají v provozu trvale). S postupem doby a díky celkovému trendu k tzv. downsizingu (přechodu na rozměrově menší, ale stejně či ještě více výkonné počítače) se ale "velké" počítače začaly zmenšovat, a do lokálních sítí se naopak začaly zapojovat stále "větší" servery (větší co do schopností a výkonu, nikoli nutně fyzických rozměrů). Proto i zde se rozdíl mezi lokálními a rozlehlými sítěmi postupně stírá. Internetworking, neboli vzájemné propojování sítí Novým trendem, který se v poslední době začal velmi výrazně prosazovat, je vzájemné propojování jednotlivých počítačových sítí. Jde zřejmě o zcela zákonitý vývoj, který následuje poté, co širší uživatelská veřejnost plně docenila možnosti a přínos počítačových sítí, a začala požadovat ještě více.
V angličtině se tomuto trendu říká internetworking, a sítím, které vznikají jako výsledek propojování jednotlivých dílčích sítí, se říká internetworks. Překlad těchto termínů do češtiny je tvrdým oříškem - internetworking je možné rozepisovat jako "vzájemné propojování sítí", ale pro substantivum "internetwork" by se velmi hodilo něco kratšího. Věcně správnější by zřejmě bylo "sousítí", ale kvůli čistotě mateřského jazyka raději zůstaňme u doslovného překladu "intersíť".
Cílem vzájemného propojování sítí je rozšířit repertoár dosud poskytovaných služeb, především o služby komunikačního charakteru, umožňující přenosy elektronické pošty a nejrůznějších souborů i do jiných sítí. Dalším cílem je pak zpřístupnění služeb a nejrůznějších systémových zdrojů jedné sítě uživatelům jiných sítí - ať již formou sdílení, prostřednictvím vzdáleného přihlašování či jinými způsoby.
Konečným cílem, ke kterému celý trend ke vzájemnému propojování sítí spěje, je pak úplné splynutí jednotlivých dílčích sítí - alespoň z pohledu uživatelů, pro které bude jedno, ve které dílčí síti se skutečně nachází, protože ve všech budou mít k dispozici stejné služby a stejné možnosti a způsoby jejich využití. Jestliže z pohledu uživatele může být vzájemné propojování sítí principiálně velmi jednoduchou záležitostí, po stránce technické jde o velmi složitou problematiku. Hlavním zdrojem její složitosti je různorodost konkrétních sítí, které se mohou výrazně lišit nejen v tom, jaké konkrétní technické prostředky používají pro vzájemnou komunikaci jednotlivých uzlů. Mnohem závažnější jsou rozdíly v celkové foncepci a filosofii, protože ty se při vzájemném propojování překonávají nejobtížněji. Proprietární a otevřená řešení
Jak jsme si již uvedli výše, navrhnout počítačovou síť může v podstatě kdokoli, a může přitom uplatnit jakékoli koncepční i technické řešení, které sám považuje za nejvhodnější. Pokud to ovšem skutečně udělá, pak se vystavuje riziku, že jiní budou za nejvhodnější považovat jiné řešení, a výsledné sítě nebudou z principu schopné spolupracovat - nebo jen velmi omezeným způsobem a za cenu značného úsilí a nákladů.
Tendence dělat si všechno po svém (a jinak než ostatní) byla v dřívější době patrná zvláště u velkých firem, vyrábějících střediskové počítače a minipočítače. Tyto firmy zřejmě zastávaly názor, že je pro ně nejvýhodnější, když si svého zákazníka k sobě doslova připoutají - tedy když mu prodají takové řešení, které bude zcela neslučitelné s řešením jiných výrobců, a nebude vycházet vstříc možnosti spolupráce s produkty jiných výrobců. Zákazník, který si takovéto řešení zakoupil, pak byl vázán na jediného dodavatele, i pokud šlo o jakékoli hardwarové doplňky, systémový i aplikační software, servis i školení uživatelů. Takovýto přístup byl snad možný v době velkých střediskových počítačů, které v jistém slova smyslu představovaly ucelený svět sám o sobě, jehož potřeby komunikace s jinými světy mohly být velmi malé. Zákazníkům se však takovýto přístup výrobců nemohl líbit - již jen z toho důvodu, že chování monopolního dodavatele je zcela zákonitě jiné, než chování toho, kdo se musí prosadit v tvrdé konkurenci. Jakmile se ale na obzoru objevila možnost propojování jednotlivých počítačů do sítí, začala uživatelům velmi vadit také vzájemná technická neslučitelnost hardwaru i softwaru, která tomuto trendu stála v cestě. V souvislosti s nástupem počítačových sítí, a ještě více pak s trendem k jejich vzájemnému propojování (internetworking-u) proto dochází ke znatelnému ústupu od produktů, koncepcí a řešení, označovaných přívlastkem proprietární, a naopak k výraznému zájmu o všechno, co se pyšní přídomkem otevřené.
Pro správné pochopení těchto trendů je třeba si zdůraznit, že nejde o ostré protiklady, které by se navzájem striktně vylučovaly: ačkoli to v praxi není příliš časté, proprietární řešení může být do značné míry otevřené. Jak tedy oba termíny správně interpretovat? Jako proprietární se dnes chápe takové řešení, které vytvořil jeden konkrétní subjekt (tj. jeden výrobce), a ten je také jediným, kdo rozhoduje o jeho dalším vývoji (úpravách, změnách, aktualizovaných verzích). Podstatné zde není to, zda je proprietární řešení zveřejněno či nikoli. Rozhodující je spíše to, že ostatní do toho "nemohou mluvit". Mohou však proprietární řešení převzít, protože to z nějakého důvodu považují za vhodné - například kvůli jeho kvalitám, častěji ale proto, že chtějí být kompatibilní s proprietárním řešením renomovaného výrobce. Z proprietárního řešení, které z vlastní vůle přejímají další subjekty, se tak stává standard, neboli řešení, akceptované a používané více subjekty. Nejčastěji se z proprietárního řešení stává standard de facto, neboli standard nepsaný, který nebyl formálně kodifikován žádnou normotvornou organizací, ale za kterým stojí buď všeobecný konsensus, častěji však snaha přizpůsobit se renomovanému výrobci. Klasickým příkladem může být architektura počítačů IBM PC a architektura počítačových sítí SNA (Systems Network Architecture) firmy IBM. Dalším příkladem původně proprietárního řešení, které se stalo nepsaným standardem - díky svým kvalitám - je způsob ovládání modemů, vyvinutý firmou Hayes. Existují však i taková proprietární řešení, z nichž se časem staly standardy de jure, neboli formální standardy, které kodifikuje a vydává některá normotvorná organizace, a které pak z tohoto titulu mohou mít i určitou míru formální závaznosti. Kromě již dříve citovaného Ethernetu může být příkladem paralelní sběrnice HP-IB, kterou si jako své proprietární řešení pro potřeby připojování měřících přístrojů vyvinula firma Hewlett-Packard, a která byla posléze standardizována americkou společností elektrotechnických a elektronických inženýrů (IEEE) jako standard IEEE 488. Dalším příkladem může být protokol NFS (Network File System), vyvinutý firmou Sun Microsystems, Inc. a určený pro transparentní sdílení souborů v sítích se servery na bázi Unixu.
Většina standardů však dnes vzniká jiným způsobem. Tak, že se sejde skupina odborníků, a ti společně navrhnou a vyspecifikují určité řešení. Nejčastěji je svolání takovéto skupiny iniciováno některou normotvornou organizací, která pak přejímá takto vzniklé řešení, a vydává jej jako svůj standard (tedy jako standard de jure). Velmi často nejde o jednorázový proces - příslušné skupiny odborníků mohou existovat dlouhodobě, a jejich práce pak má průběžný charakter. Zajímavé je i to, odkud se rekrutují lidé, kteří v těchto odborných pracovních skupinách působí: vedle odborníků z akademických kruhů zde mají významné zastoupení také zástupci nejrůznějších výrobců výpočetní techniky. Je to zřejmě přirozené, protože tito výrobci mají často nezanedbatelný odborný a vědecko-výzkumný potenciál. Navíc je v jejich bytostném zájmu být informováni o všem, co se připravuje, a moci do toho také určitým způsobem zasahovat. Je asi přirozené, že názory různých výrobců mají na takovémto fóru různou "váhu", ale nikdy by zde nemělo dojít k tomu, aby jeden výrobce diktoval svou představu ostatním, a tím vlastně jen zaštítil své proprietární řešení autoritou příslušné normotvorné organizace. Vraťme se nyní zpět k tomu, co je vlastně obsahem přívlastkem "otevřený". V zásadě jde o takové řešení, které je připraveno na spolupráci s jinými produkty či systémy a předem s ní počítá - je tedy "otevřeno" takovéto spolupráci (odsud pak přívlastek "otevřený"). Problém je ovšem v míře takovéto připravenosti či otevřenosti, která není nijak závazně stanovena. Z tohoto důvodu je faktický obsah pojmu "otevřený systém" značně široký. Zlé jazyky dokonce tvrdí, že je stejně otevřený, jako samotný otevřený systém. Různí výrobci pak této obsahové neujasněnosti využívají pro zvýšení prodejnosti svých produktů, které označují jako otevřené i přesto, že možnosti spolupráce s jinými systémy nevychází příliš vstříc. Skutečně otevřené systémy jsou charakteristické především tím, že svou spolupráci s jinými systémy řeší pomocí všeobecně uznávaných a používaných standardů - tedy tím, že samy používají a důsledně dodržují takovéto standardy. Pokud stejný přístup zvolí i druhá strana, pak by vzájemné kompatibilitě různých systémů neměly stát v cestě žádné principiální překážky. Skutečně otevřené systémy proto vychází maximálně vstříc vzájemnému propojování sítí stejného i nestejného typu, zatímco propojování proprietárních sítí různých výrobců bývá velmi obtížné, někdy až nemožné.