


RPC I.
V minulých třech dílech jsme se podrobněji zabývali celkovou filosofií i některými implementačními aspekty protokolu NFS, který má v rodině protokolů TCP/IP na starosti plně transparentní sdílení souborů v prostředí počítačových sítí. Kromě své samotné podstaty je ale tento protokol zajímavý také tím, že pro jeho praktickou implementaci byl poprvé ve významnějším měřítku použit mechanismus, označovaný jako RPC (Remote Procedure Call). Dnes se podrobněji seznámíme s celkovou filosofií a základními aspekty tohoto mechanismu, a v příštím dílu si ukážeme, jak je konkrétně použit pro implementaci protokolu NFS v prostředí Unixu.
Nejprve si ale zopakujme, jakým principiálním způsobem je v protokolu NFS řešen požadavek klienta na přístup ke vzdálenému souboru: k uspokojení tohoto požadavku je nutné provedení určitých akcí (např. čtení či zápisu na disk), které ale musí proběhnout na tom počítači, na kterém se soubor skutečně nachází - tedy na počítači v roli serveru. Na straně klienta, který o přístup ke vzdálenému souboru žádá, je proto zformulován požadavek na provedení těchto akcí, je sestaven ve formě zprávy, a tato je odeslána serveru. Ten zprávu přijme, provede požadované akce, a jejich výsledek vrátí zpět klientovi jako svou odpověď.
Nyní si zkusme představit, jakým konkrétním způsobem může být toto obecné schéma realizováno. Aplikace, která požadavek na přístup ke vzdálenému souboru vznáší, si vzhledem k plně transparentnímu sdílení nemusí vůbec uvědomovat, že jde o vzdálený soubor - svou žádost tedy formuluje přesně stejně, jako kdyby šlo o místní soubor (v prostředí Unixu formou systémového volání, viz minulý díl). Skutečnost, že jde o vzdálený soubor, si plně uvědomuje až ta programová entita, která příslušný požadavek skutečně vyřizuje. Ta si také musí být vědoma, že pracuje v prostředí sítě, musí si uvědomovat existenci vzdálených uzlů a musí znát způsob, jak s nimi komunikovat. Tato konkrétní programová entita, kterou ve víceúlohovém prostředí bude nejspíše samostatný proces, tedy nejprve sestaví příslušný požadavek ve formě zprávy, tu odešle, a pak čeká na odpověď serveru. Toto čekání přitom bude nejspíše realizováno jako suspendování příslušného procesu (tedy jeho převedení ze stavu "probíhající" do stavu "čekající"), s požadavkem na následné aktivování v okamžiku příchodu odpovědi (která bude zřejmě signalizována prostřednictvím mechanismu přerušení).
Zkusme si právě popsaný postup zrekapitulovat: proces, který dostal za úkol uspokojit požadavek na přístup ke vzdálenému souboru, zajistí provedení příslušných akcí prostřednictvím akcí typu odeslání zprávy a čekání na vnější událost (která je z jeho pohledu asynchronní).
Tento postup je samozřejmě možný, a v praxi je také hojně používán. Je ovšem v zásadním rozporu se současnou představou o tom, jak správně psát programy - tedy se zásadami strukturovaného programování. Vzhledem k tomu pak neumožňuje nasadit osvědčené metody návrhu a vývoje rozsáhlých programových celků, které jsou na strukturovaném programování založeny.
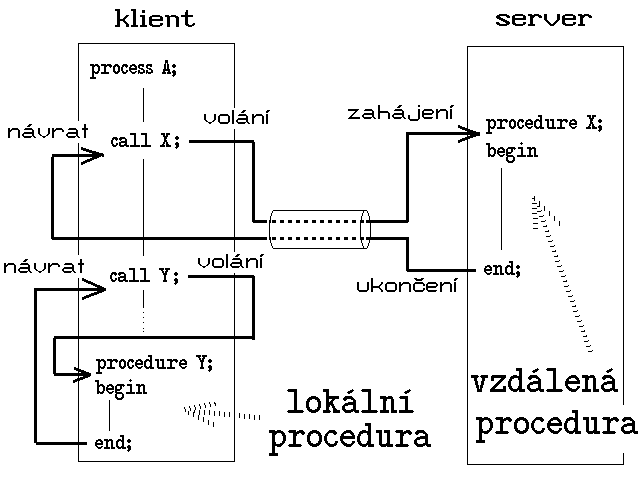 |
Tomu, aby se tato představa mohla aplikovat i na zajištění přístupu ke vzdáleným souborům, stojí v cestě jedna významná skutečnost - vlastní výkonné akce nebudou probíhat na tom počítači, na kterém je požadavek na jejich provedení vznesen. Pokud bychom tedy chtěli vyhovět zásadám strukturovaného programování, potřebovali bychom nějaký mechanismus, který by nám umožnil volat procedury na jednom uzlovém počítači, ale skutečně je provádět na jiném uzlovém počítači. Tedy volat takové procedury, které jsou z pohledu volajícího vzdálenými procedurami (remote procedures). Představu volání takovéto vzdálené procedury ukazuje opět obrázek 78.1.: požadavek na provedení vzdálené procedury nechť vznáší programová entita (proces A) na straně klienta, a to obvyklou formou volání procedury. Tato je ovšem vzdálená, proto je její skutečné provádění zahájeno na vzdáleném uzlu (serveru). Když provádění této procedury skončí, dojde i na straně klienta k předání řízení bezprostředně za místo volání vzdálené procedury (tedy k běžnému návratu z volané procedury).
Mechanismus, který právě naznačený způsob volání vzdálených procedur umožňuje, se pak příznačně označuje jako RPC (Remote Procedure Call, doslova: volání vzdálených procedur). V ideálním případě zcela zakrývá jakýkoli rozdíl mezi voláním místní a vzdálené procedury, takže volající si ani nemusí být vědom, že jím volaná procedura se ve skutečnosti provádí na vzdáleném počítači (dosažení tohoto ideálního stavu ale stojí v cestě některé technické problémy, o kterých se zmíníme později).
Zastavme se nyní u toho, v čem tkví skutečná odlišnost vzdáleného volání procedur od původní představy explicitního zasílání zpráv a čekání na odpovědi. Samotná komunikace mezi dvěma uzly sítě bude vždy muset mít formu předávání zpráv - rozdíl je zde pouze v tom, kdo a jak bude tyto zprávy sestavovat a odesílat, a také čekat na odpovědi a vyhodnocovat je. Vžijme se do postavení toho, kdo píše programovou entitu, skutečně zajišťující přístup ke vzdáleným souborům - v souladu s obrázkem 78.1. proces A. Bez mechanismu RPC musí proces A sám explicitně sestavovat a odesílat zprávy, vhodným způsobem čekat na odpovědi a tyto pak vyhodnocovat. Ten, kdo píše (a hlavně ladí) zdrojový tvar tohoto procesu, se pak musí obejít bez všech podpůrných prostředků, které pro vývoj a tvorbu strukturovaných programů existují.
 |
Pokud bychom tedy vše maximálně zjednodušili, mohli bychom se na mechanismus RPC dívat jako na "vrstvičku", která překrývá explicitní komunikaci se vzdáleným uzlem (založenou na předávání zpráv), a nahrazuje ji voláním lokálních procedur (spojek).
Ve skutečnosti je ovšem úloha mechanismu RPC mnohem obecnější. Kromě příslušných spojek na straně klienta tento mechanismus definuje i obdobné spojky na straně serveru, které přijímají zprávy od spojek klientů, a na jejich základě pak volají výkonné procedury, které zajistí provedení požadovaných akcí - tedy procedury, které jsou z pohledu klienta (procesu A) vzdálené, ale pro spojku na straně serveru již jsou lokální! Dále je součástí definice mechanismu RPC i přesný způsob komunikace mezi spojkami klientů a serverů, a v neposlední řadě i repertoár vzdálených procedur, možnosti a způsoby rozšiřování tohoto repertoáru atd.
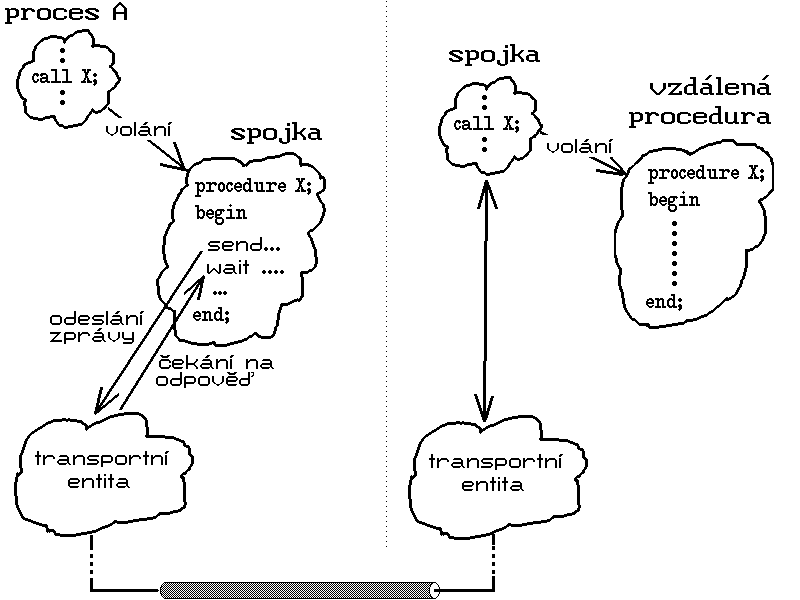
Zastavme se ale ještě u některých technických aspektů mechanismu RPC, které nám umožní lépe pochopit jeho samotnou podstatu. V souladu s obrázkem 78.2. vycházejme opět z toho, že tím, kdo na straně klienta mechanismus RPC bezprostředně využívá (aniž si to nutně musí uvědomovat), je proces A. Pokud například potřebuje načíst část souboru, který se nachází na vzdáleném počítači, bude za tímto účelem volat proceduru (např. read), která je ve skutečnosti spojkou (stub). Této spojce-proceduře přitom předá všechny potřebné parametry stejným způsobem, jako kterékoli jiné lokální proceduře. Spojka pak na základě svého volání sestaví zprávu pro svou partnerskou spojku na straně serveru, a v ní mj. uvede, která vzdálená procedura má být provedena. Parametry, které spojka klienta dostala při svém volání, však ve skutečnosti "patří" vzdálené proceduře. Spojka klienta je proto převede do takového tvaru, který je vhodný pro přenos (tomuto úkonu se říká marshalling, nebo též: serializing), a připojí je ke zprávě, odesílané spojce serveru. Tato spojka pak zprávu přijme, v ní obsažené parametry "rozbalí" (provede tzv. unmarshalling, též: deserializing), a zajistí volání požadované procedury. Tato je pro spojku na straně serveru lokální procedurou, a proto ji všechny potřebné parametry předá způsobem, obvyklým pro lokální procedury. Jakmile výkonná procedura skončí, vrátí řízení tomu, kdo ji volal - tedy spojce serveru. Ta vezme všechny případné výstupy, upraví je do vhodného tvaru pro přenos, a odešle zpět spojce klienta.
S předáváním parametrů je ovšem spojena hned celá řada technických problémů. Nejjednodušší je situace v případě, kdy jsou parametry vzdálené procedury volány hodnotou. Pak totiž stačí vytvořit jejich kopii, tu odeslat spojce serveru, a při skutečném volání vzdálené procedury je opět předat jako parametry volané hodnotou. V případě volání referencí (neboli: odkazem) dostává volaná procedura na straně klienta (tj. spojka) pouze ukazatel na objekt, který je jejím skutečným parametrem. Tento objekt však existuje jen na straně klienta, a proto není možné použít tentýž ukazatel i na straně serveru a předat jej při skutečném volání vzdálené proceduře. Možným řešením je v tomto případě strategie copy/restore: ta předpokládá, že objekt, na který ukazatel ukazuje, je nejprve zkopírován (resp. přenesen) i na server. Vzdálená procedura pak při svém volání dostane ukazatel na tento zkopírovaný exemplář programového objektu, který pak může v rámci své činnosti příslušným způsobem modifikovat. Jakmile provádění vzdálené procedury skončí, je dotyčný objekt zase zkopírován zpět na klienta.
Další okruh problémů je pak spojen s tím, že různé uzlové počítače mohou používat odlišné konvence pro reprezentaci nejrůznějších operandů, které jsou předávány v roli parametrů vzdálených procedur. Proto je v rámci "balení" parametrů před přenosem (marshalling, serializing) a při následném "rozbalení" třeba provádět i potřebné konverze. O tom, jak je tato otázka řešena v prostředí TCP/IP sítí, si ale povíme v dalších pokračováních.