


Část 3. - Předpoklady vzájemné spolupráce
V prvních dvou dílech volné série článků na téma Interoperabilita jsme se zamýšleli nad vzájemným postavením a nad možnými formami spolupráce dvou operačních systémů, stojících na různých platformách: MS DOSu a Unixu. Nyní se zaměříme na to, bez čeho by jejich spolupráce nebyla možná - na vzájemné propojování počítačů.
Interoperabilita jako spolupráce různých platforem se týká různých úrovní - to jsme si řekli již v první části této volné série článků. Na nejvyšší úrovni jde o spolupráci dvou aplikací, které pracují v prostředí různých operačních systémů. Na bezprostředně nižší úrovni jde o spolupráci samotných operačních systémů, které si chtějí navzájem sdílet své systémové zdroje - nejčastěji soubory a tiskárny - a předkládat je "svým" aplikacím stejně, jako vlastní systémové zdroje. Jakým způsobem to mohou dělat (transparentně a netransparentně v případě sdílení souborů, s využitím spoolingu v případě tiskáren) a jaký přitom může být mezi nimi vztah (terminál-hostitelský počítač, peer-to-peer či klient-server), to jsme si na příkladu Unixu a MS DOSu ukazovali v prvních dvou částech. Nezbytným předpokladem pro interoperabilitu na těchto dvou nejvyšších úrovních je ale to, aby spolu příslušné operační systémy dokázaly vůbec komunikovat.
I když jsme si minule ukázali, že Unix a MS DOS dokáží vedle sebe existovat i na jediném počítači, jejich vzájemná interoperabilita začíná být zajímavá až v prostředí počítačových sítí, kde každý z těchto operačních systémů běží na vlastním počítači, a tyto jsou spolu určitým způsobem propojeny. Začněme proto tím, jak může být vzájemné propojení počítačů prostřednictvím sítě řešeno.
Propojit dva počítače tak, aby spolu mohly komunikovat, lze mnoha různými způsoby. Totéž samozřejmě platí i pro vzájemné propojování více počítačů do skutečné sítě. V principu tedy má každý výrobce možnost udělat si vše podle svého - ovšem s tím rizikem, že jeho řešení nebude kompatibilní s řešením jiných výrobců, a že tedy příslušné sítě nepůjdou vzájemně propojit.
Tendence výrobců dělat si všechno po svém se naštěstí neudržela (jak jsme si řekli již v prvním článku série), a byla nahrazena snahou vytvářet otevřené systémy, které se vzájemným propojováním od začátku počítají a vychází mu vstříc. Konkrétně v oblasti počítačových sítí to znamenalo přechod od mnoha vlastních řešení k několika málo standardním síťovým architekturám. Ty vznikaly různým způsobem - od zeleného stolu, zobecněním něčeho již existujícího, či kombinací obou přístupů. Avšak ještě dříve, než se jimi budeme zabývat konkrétně, se zastavíme u společných vlastností všech síťových architektur, a samozřejmě i u toho, co si pod pojmem síťová architektura vlastně představovat.
Sítím vládnou vrstvy
Vytvořit takový software, který by dokázal zajistit vše potřebné pro komunikaci uzlových počítačů v síti, není jednoduché. Právě naopak, je to pořádně těžké. Takže se nelze divit, že se i zde uplatnila osvědčená technika, která dokáže učinit řešitelným i takový rozsáhlý problém, který by jinak řešitelný nebyl. Svůj původ má tato technika v dávném pravidle "divide et impera", ze kterého si novodobá matematická informatika vyrobila princip dekompozice, neboli rozdělení jednoho velkého problému na několik menších, samostatně řešitelných problémů. Kde ovšem udělat pomyslný řez, který by samostatně řešitelné části problému vymezoval?
V případě počítačových sítí se přímo nabízí vést tento řez horizontálně, a vytvořit celou hierarchii vrstev. Každé z nich pak vyspecifikovat, co se od ní bude chtít, a co naopak bude mít k dispozici. Má-li být však být každá vrstva řešitelná samostatně, musí být navíc ještě velmi přesně definováno rozhraní mezi jednotlivými vrstvami i způsob jejich vzájemné komunikace.
Ukažme si nyní, jaká je obecná představa tohoto rozhraní a vzájemné komunikace vrstev.
Entity
Úkoly, které má určitá konkrétní vrstva na starosti, mohou být implementovány programovými objekty takového typu, jaký podporuje příslušný operační systém - mohou to tedy být samostatné procesy (ve víceúlohovém prostředí), rezidentní programy (v jednoúlohovém prostředí MS DOSu), případně vhodné rutiny či podprogramy. V terminologii počítačových sítí se tyto programové objekty zahrnují pod společný název entity.
Každá entita tedy "patří" do určité vrstvy, a má na starosti implementaci služeb, poskytovaných touto vrstvou. Zajímavou otázkou je pak to, zda v každé vrstvě je vždy jen jedna takováto entita, nebo jich může být více. Může jich být více, a to hned ze dvou důvodů: jak uvidíme záhy, je často velmi žádoucí, aby jednotlivé vrstvy poskytovaly různé varianty služeb téhož typu (např. tzv. spolehlivé i nespolehlivé přenosové služby, viz dále), a každá z těchto variant pak bývá zajišťována samostatnou entitou. Dalším důvodem je skutečnost, že vrstvy poskytují v obecném případě tytéž služby více subjektům najednou (například více současně provozovaným aplikacím). V jednoúlohovém prostředí je pak nutné zajistit možnost vícenásobného využití entit reentrantností příslušných podprogramů či rutin, zatímco ve víceúlohovém prostředí je přirozenějším řešením dynamické vytváření samostatných procesů na základě jejich skutečné potřeby.
Přechodové body mezi vrstvami
V každé vrstvě je tedy v obecném případě více entit. Jak ale mají být rozlišovány? Když například entita jedné vrstvy chce předat výsledek své práce entitě vrstvy bezprostředně vyšší, nebo chce poslat nějaká data určité entitě jiného uzlového počítače, jakým způsobem má tuto entitu určit? To je velmi zajímavá otázka. Na první pohled se jako nejpřirozenější řešení nabízí přidělit každé entitě jednoznačný identifikátor, a jednotlivé entity pak určovat pomocí těchto identifikátorů. Je zde ale jeden technický problém - jestliže entity mohou vznikat dynamicky (a také dynamicky zanikat), musely by jim být i jejich identifikátory přidělovány dynamicky. V rámci jednoho uzlového počítače by to ještě mohlo být únosné, ale nikoli již při vzájemné komunikaci různých počítačů, kdy entita jednoho uzlového počítače potřebuje identifikovat entitu jiného uzlového počítače.
Pak je zde ještě další důvod, který by bylo možné označit za koncepční. Jestliže mají být jednotlivé vrstvy odděleny tak, aby mohly být řešeny samostatně a nezávisle na způsobu řešení ostatních vrstev (resp. obou sousedních), pak by je měly zajímat služby, a nikoli konkrétní entity (procesy, podprogramy), které je zajišťují. Jestliže například entita určité vrstvy požaduje od bezprostředně nižší vrstvy službu A, měla by svůj požadavek adresovat "tomu, kdo poskytuje službu A", a nikoli "procesu XY" - protože je docela dobře možné, že "službu A" bude v daném případě, v daný moment a pro daného žadatele poskytovat jiný proces, než "proces XY".
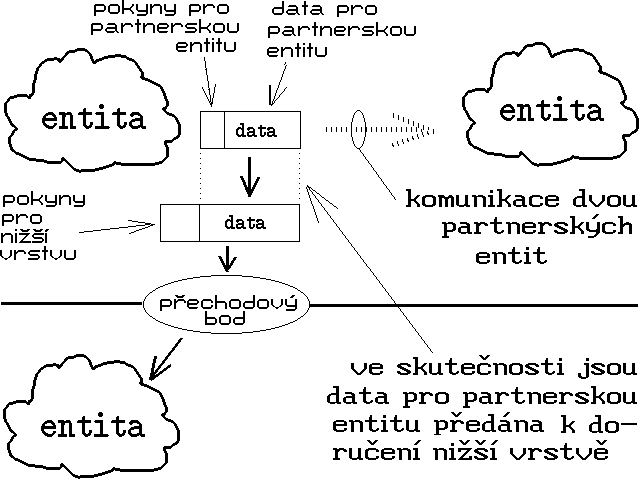
Entity jednotlivých vrstev se proto neodkazují na sebe přímo (prostřednictvím identifikátorů entit), ale pouze nepřímo. Používají k tomu zvláštní objekty, které tvoří přechodové body mezi jednotlivými vrstvami - viz obr. 1. Vazba jednotlivých entit na tyto přechodové body má pak dynamický charakter, a může se podle potřeby měnit. Je pak možné i to, aby jedna a tatáž entita poskytovala své služby prostřednictvím více přechodových bodů.
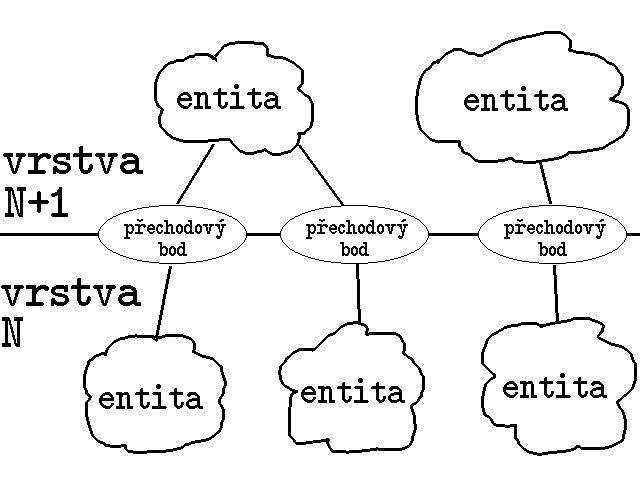 |
Komunikace mezi vrstvami
 |
 |
 |
Peer-to-peer
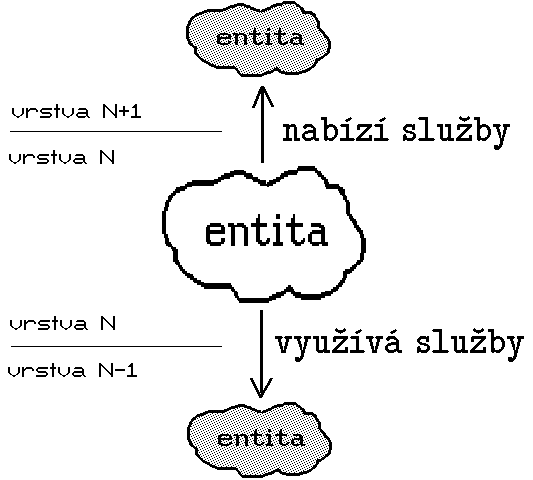
Nesmíme ovšem zapomínat také na to, že hlavním úkolem síťového softwaru je přenos dat mezi uzlovými počítači sítě. Jak to ale koresponduje s představou, že jednotlivé vrstvy komunikují pouze vertikálně? Odpověď naznačuje obrázek 5: partnerem pro entitu určité vrstvy, se kterým spolupracuje, vyměňuje si data a nejrůznější další údaje, je vždy entita stejnolehlé vrstvy jiného uzlového počítače, v angličtině označovaná jako peer.
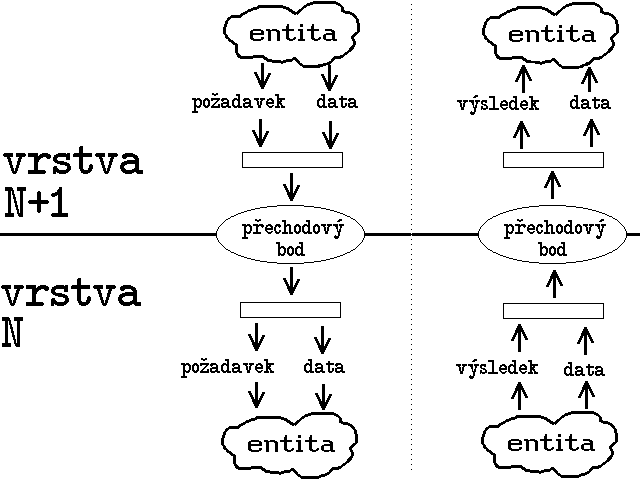
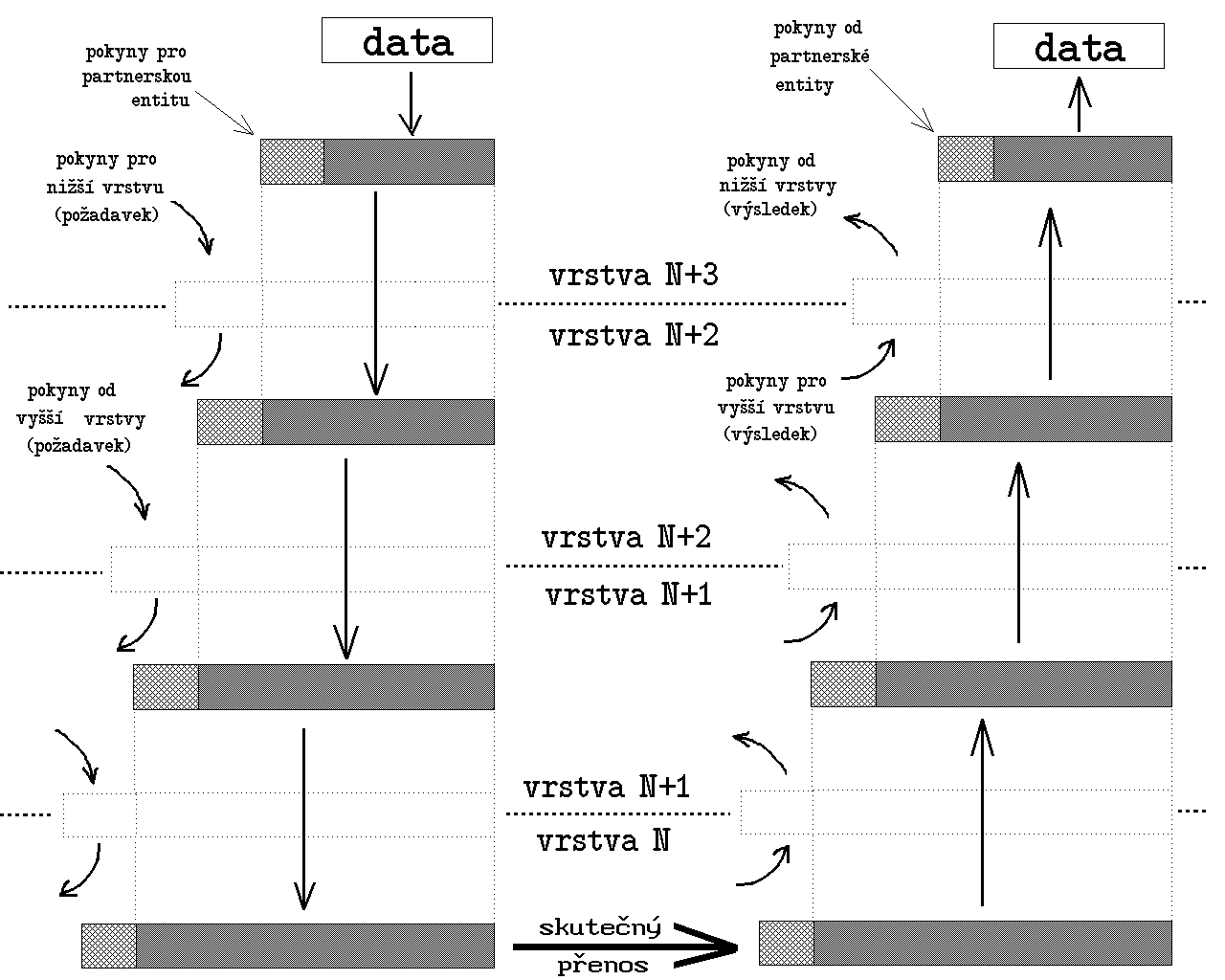
Problém je ovšem v tom, že kromě nejnižší vrstvy spolu takovéto dvě entity (peers) nemohou komunikovat přímo, ale pouze prostřednictvím služeb nižších vrstev. Jestliže tedy chce určitá entita poslat své partnerské (peer) entitě na jiném uzlovém počítači nějaká data, ve skutečnosti je předá své bezprostředně nižší vrstvě k doručení. Má-li ovšem partnerská entita tušit, jaká data to jsou, od koho pochází, co s nimi má udělat atd., musí k nim odesilatel přidat ještě nějaké doplňující informace, určené pro partnerskou entitu.
Zajímavý je způsob, jakým se tyto doplňující informace přenáší. V předchozím odstavci jsme předpokládali, že entita vyšší vrstvy předává entitě nižší vrstvy balíček, který má dvě části: část obsahující data, a část obsahující pokyny pro entitu nižší vrstvy. Datová část je ale sama o sobě také "balíčkem", který má opět dvě části - jednou z nich jsou právě doplňující informace pro partnerskou entitu odesilatele, a druhou "čistá" data, která mají být partnerské vrstvě doručena. Entita nižší vrstvy však tento "menší balíček" již nerozbaluje. Sama si "vezme" jen ty pokyny, které jsou určeny pro ni (a které již dále nikomu nepředává), a zbytek považuje za dále nedělitelná data, se kterými naloží podle obdržených pokynů. Celý postup názorně ilustruje obrázek 5.
 |
Protokoly
 |
Výběr těchto pravidel i jejich konkrétního naplnění (pokynů) je determinován především úkoly příslušné vrstvy, na které obě entity pracují - tedy charakterem poskytovaných služeb. I přesto ale existuje dosti velká variabilita v tom, jak mohou být služby jednoho a téhož druhu prakticky implementovány.
Konkrétní soubor pravidel, který přesně vymezuje vzájemnou komunikaci dvou entit stejnolehlých vrstev a jejich součinnost při poskytování služeb určitého druhu, se označuje jako protokol. Jedním z jeho charakteristických rysů je právě skutečnost, že je vždy vztažen k určité vrstvě, resp. že v každé vrstvě vrstvového modelu se používá jiný protokol.
Protokol tedy specifikuje přesný formát "balíčků", které si partnerské entity vyměňují, stanovuje význam jejich jednotlivých částí, určuje konkrétní postup při vzájemné komunikaci (jak má jedna strana reagovat na určitou akci druhé strany) a mnoho dalších důležitých věcí.
Síťové architektury
Protokol tedy můžeme chápat jako konkrétní představu o tom, jak mají být zajišťovány služby v rámci určité vrstvy. Kdo ale rozhoduje o tom, jaké služby má která vrstva poskytovat? A kdo vlastně určuje, kolik různých vrstev má existovat, a jak mají být koncipovány?
Názorů na to, do kolika vrstev má být síťový software rozdělen, co má mít která vrstva na starosti a jak konkrétně má své úkoly plnit, může být samozřejmě velmi mnoho. Každý takovýto názor však již představuje dosti ucelenou představu o tom, jak má počítačová síť vypadat a jak má fungovat. Proto se v této souvislosti hovoří o tzv. síťové architektuře.
Každá síťová architektura tedy specifikuje rozdělení síťového softwaru na určitý počet vrstev, a těmto vrstvám přiděluje konkrétní úkoly. Kromě toho jsou součástí síťové architektury i konkrétní protokoly pro jednotlivé vrstvy.
Různé síťové architektury se pak liší v tom, kolik vrstev považují za optimální, jaké úkoly jednotlivým vrstvám přisuzují, a v neposlední řadě i tím, jak si představují konkrétní naplnění těchto úkolů (tj. konkrétní protokoly jednotlivých vrstev).
Za zmínku však stojí i skutečnost, že síťová architektura v právě naznačeném smyslu může počítat s jistou variabilitou. Pro jednu a tutéž vrstvu může nabízet více alternativ, lišících se v některých detailnějších aspektech poskytovaných služeb i v konkrétních protokolech pro jejich implementaci. V rámci každé síťové architektury tedy může pro každou vrstvu existovat více různých protokolů. Proto se v této souvislosti hovoří i o tzv. rodině protokolů (protocol suite) jako o soustavě všech protokolů, které příslušná síťová architektura obsahuje.
Jak jsme si již naznačili výše, nemusí to vždy být protokoly alternativní, které by se navzájem vylučovaly. U vyšších vrstev je naopak častější případ, kdy jsou v rámci jedné vrstvy poskytovány různé druhy služeb, implementované různými protokoly - každá aplikace si pak vybere ty z nich, které jsou pro ni nejvýhodnější. Tím si sama vytváří jakýsi "výběr" či "řez" rodinou protokolů, v rámci kterého je každá vrstva "zabydlena" již jen jedním konkrétním protokolem. Pak hovoříme o tzv. sestavě protokolů (protocol stack).
Spolehlivé vs. nespolehlivé služby
Zatím jsme si však ještě nenaznačili, jaký smysl má nabízet v rámci určité vrstvy více různých protokolů, resp. více variant služeb, ani v čem se tyto varianty mohou lišit.
Začněme nejprve otázkou spolehlivosti. Jakýkoli přenos dat v počítačové síti je vždy zatížen určitou mírou chybovosti - může se tedy stát, že příjemce obdrží jiná data, než jaká mu odesilatel původně poslal. Záleží samozřejmě na tom, jak často k takovémuto poškození přenášených dat dochází, jakého je charakteru, a o jak důležitá data se jedná. V souvislosti s tím je pak zajímavá otázka, kdo se má starat o nápravu.
Nejprve se ale zamysleme nad tím, jaké možnosti nápravy vůbec existují a "kolik stojí". Teprve pak má totiž smysl uvažovat o tom, komu je nejvýhodnější nápravu svěřit.
Možnosti nápravy jsou v podstatě dvě. První z nich spočívá v použití tzv. samoopravných kódů, které příjemci poškozených dat umožňují nejen rozpoznat chyby, ale také opravit je vlastními silami. Takovéto kódy existují, ale jejich použití je značně neefektivní - zavádí totiž příliš velkou míru redundance, která se v konečném efektu projevuje tak, že vedle "užitečných" dat se musí přenášet i velmi velký objem zabezpečujících informací. Druhou možností je použít tzv. detekční kódy, které jsou sice mnohem úspornější, ale na druhé straně umožňují chybu pouze detekovat, a nikoli již opravit. Po detekci chyby však může následovat zpráva odesilateli se žádostí o opakované vyslání chybně přijatých dat, nebo naopak potvrzení o tom, že data byla přijata bez chyb - této technice se říká příznačně potvrzování (acknowledgement).
| Spolehlivé | Nespolehlivé |
| při detekci chyby v přijatých datech jsou podnikány nápravné akce (odesilateli se signalizuje, že má data vyslat znovu) | při detekci chyby v přijatých datech nejsou podnikány nápravné akce (data jsou zahozena) |
| má větší režii (na zajištění spolehlivosti) | má menší režii (nemusí zajišťovat spolehlivost) |
| je méně efektivní (kvůli režii se spolehlivostí nedokáže plně využít přenosových možností) | je efektivnější (dokáže lépe využít přenosovu kapacitu, tj. přenést více dat) |
Spolehlivým přenosem (reliable transmission) se pak chápe takový přenos, při kterém se o nápravu případných chyb stará ten, kdo přenos zajišťuje. Nespolehlivý přenos je pak takový, u kterého ten, kdo přenos zajišťuje, pouze detekuje chyby, ale nepodniká žádné nápravné akce pro jejich ošetření (tj. chybně přijatá data jednoduše zahazuje). Zasadíme-li si právě vyslovené definice do prostředí vrstvových modelů, pak o spolehlivý přenos v rámci určité vrstvy se jedná v případě, kdy příslušná vrstva sama podniká potřebné nápravné akce (formou potvrzování), a nespolehlivým přenosem je takový případ, kdy daná vrstva nápravné akce nepodniká (a přenechává je vyšším vrstvám). Obecně je tedy spolehlivý přenos zatížen určitou režií, a je tudíž méně efektivní. Naopak nespolehlivý přenos má režii mnohem menší, a může proto být efektivnější (tj. rychlejší).
Nyní již se můžeme vrátit k naší původní otázce: které vrstvy mají zajišťovat spolehlivost? Nebo jinak: které vrstvy mají poskytovat spolehlivé přenosové služby, a které nespolehlivé přenosové služby?
Odpověď má přinejmenším dva aspekty: technický a ekonomický. Po technické stránce jde o to, že spolehlivý přenos není nikdy stoprocentně spolehlivý (vzhledem k účinnosti detekčních kódů, viz výše). Záleží pak na uživateli spolehlivé přenosové služby, zda ji bude považovat za dostatečně spolehlivou či nikoli. Jde-li například o přenos naměřených dat o stavu počasí, drobná chyba ve velkém objemu dat se nejspíše dá tolerovat. Avšak půjde-li o přenos bankovních transakcí mezi dvěma finančními institucemi, může mít jediná drobná chybička nedozírné následky. V takovém případě bude nezbytné, aby si uživatel (resp. vyšší vrstvy) zajišťoval spolehlivost znovu sám - kromě toho, že se o spolehlivost snaží i nižší vrstva, a má s tím spojenu nezanedbatelnou režii. Pak se ovšem zákonitě nabízí otázka, zda je vhodné usilovat o dosažení spolehlivosti ve více vrstvách současně (a sčítat režie s tím spojené), nebo zda by nebylo vhodnější ponechat zajištění spolehlivosti až na tom, kdo ji skutečně potřebuje (tj. na koncovém uživateli resp. na vyšších vrstvách), a od nižších vrstev požadovat pouze nespolehlivý přenos. Svou roli přitom samozřejmě hraje i kvalita přenosových cest, a z nich vyplývající skutečná četnost chyb. Takže záleží i na tom, zda jsou příslušné přenosové služby poskytovány například v lokálních sítích na bázi Ethernetu (které jsou samy o sobě relativně velmi spolehlivé), nebo naopak v sítích rozlehlých (které bývají výrazně nespolehlivější).
Druhý aspekt je ekonomický. Postavíme-li se na pozici provozovatele takové sítě, která bude své přenosové služby poskytovat někomu za úplatu, bude v našem zájmu nabízet služby co nejdokonalejší, za které si budeme moci účtovat co nejvíce. Z tohoto pohledu jsou jednoznačně výhodnější služby spolehlivé. Budeme-li naopak v pozici někoho, kdo si svou síť buduje a provozuje sám, pak tuto motivaci mít nebudeme, a zřejmě převáží aspekty technické, které na nižších vrstvách dávají přednost službám nespolehlivým, a zajištění spolehlivosti svěřují až vrstvám vyšším.
Spojované vs. nespojované služby
| spojovaná komunikace | nespojovaná komunikace |
| mezi odesilatelem a příjemcem je navázáno spojení | mezi odesilatelem a příjemcem není zřizováno spojení |
| při navázání spojení vzniká logická cesta mezi příjemcem a odesilatelem | mezi odesilatelem a příjemcem není vytyčena žádná logická cesta |
| veškerá data jsou přenášena stejnou cestou (vytyčenou při navazování spojení) | pro každý jednotlivý "kus" dat je cesta jeho přenosu volena individuálně (tj. data nemusí být vždy přenášena stejnou cestou) |
| větší jednorázová počáteční režie (na navazování spojení) | menší (nulová) počáteční režie |
| menší režie na vlastní přenos dat | větší režie na vlastní přenos dat (především na volbu dalšího směru přenosu) |
| výhodnější pro přenos větších objemů dat | výhodnější pro přenos menších objemů dat |
Pro vysvětlení rozdílu mezi oběma variantami si pomůžeme analogií s telefonním hovorem a listovní poštou. Telefonní hovor je příklad komunikace spojovaného charakteru. Chceme-li někomu zavolat, musíme s ním nejdříve navázat spojení (vytočit jeho telefonní číslo). Druhý účastník musí existovat (mít telefon), a musí být schopen (a ochoten) naše volání přijmout. Teprve po navázání spojení (když volaný zvedne sluchátko) může dojít k vlastnímu přenosu (hovoru), a následně musí dojít ke zrušení spojení (ukončení hovoru zavěšením).
Když naopak někomu posíláme dopis listovní poštou, vložíme jej do obálky, na kterou napíše adresu příjemce, a dopis předáme poště k doručení. Ta předem nezjišťuje, zda adresát skutečně existuje a zda bude ochoten náš dopis přijmout - převezme jej a snaží se jej doručit v dobré víře, že to bude možné. Listovní pošta je tedy příkladem nespojovaného charakteru komunikace, při kterém nedochází k navazování spojení mezi oběma koncovými účastníky a tím i ke vzniku pevně dané cesty, po které by následně proudila všechna přenášená data, jako u spojované komunikaci. Při nespojované komunikaci si naopak každý jednotlivý "kus" dat razí svou cestu k příjemci sám, opatřen jeho úplnou adresou.
Výhody obou variant jsou vcelku zřejmé: u spojované komunikace je větší jednorázová režie na počáteční navázání spojení, a naopak menší průběžná režie na přenos vlastních dat (která jsou vždy přenášena stejnou cestou, vytyčenou při navazování spojení). Naproti tomu u nespojované komunikace je jednorázová počáteční režie nulová (neboť odpadá navazování spojení), ale větší je zase režie na vlastní přenos dat (připadající hlavně na neustále se opakující volbu dalšího směru přenosu jednotlivých "kusů" dat).
Obecně pak lze konstatovat, že spojovaný způsob přenosu je výhodnější pro větší objemy dat, zatímco nespojovaný je výhodnější pro menší objemy přenášených dat.
V čem se síťové architektury liší
Nyní se již můžeme vrátit k síťovým architekturám jako takovým. Jak jsme si již naznačili, síťová architektura může vzniknout různými způsoby - od zeleného stolu, neboli tak, že někdo ji nejprve "vymyslí", a teprve pak ji implementuje. Opačný přístup je takový, že síťová architektura vznikne zobecněním něčeho již existujícího, co se mohlo i určitou dobu vyvíjet.
Vezměme si jako příklad dvě význačné síťové architektury, na kterých lze názorně dokumentovat nejen odlišný způsob vzniku, ale i odlišnou základní koncepci.
Referenční model ISO/OSI
Prvním příkladem bude tzv. Referenční model ISO/OSI, i když není síťovou architekturou v takovém smyslu, jaký jsme si zavedli (neboť neobsahuje konkrétní protokoly pro jednotlivé vrstvy - tyto vznikaly a neustále vznikají samostatně). Referenční model ISO/OSI (Open Systems Interconnection - Basic Reference Model, dokument ISO IS 7498) je ukázkovým příkladem koncepce, která vznikala "od zeleného stolu", i se všemi typickými důsledky. Je koncipován spíše maximalisticky: zavádí poměrně velký počet vrstev (celkem sedm), a přiděluje jim i takové úkoly a funkce, které by podle mínění autorů "mohly být někdy někomu užitečné". Pro potřeby praktické realizace se pak hledají rozumně implementovatelné podmnožiny. Další zajímavostí referenčního modelu je skutečnost, že jej vymysleli "lidé od spojů", kteří mu pak vcelku pochopitelně vtiskli svou vlastní mentalitu a pohled na svět. Ten se projevuje zejména tím, že referenční model (alespoň ve své původní podobě) předpokládal pouze služby spojovaného charakteru (nezapomeňme: telefonní systémy pracují spojovaně!), a navíc spolehlivé (na každé úrovni). Teprve později se pod tlakem "lidí od počítačů" prosadily do referenčního modelu také služby nespojované a nespolehlivého charakteru.
Referenční model ISO/OSI předpokládá celkem sedm vrstev, kterým přisuzuje následující úkoly:
|
Rodina protokolů TCP/IP
Rodina protokolů TCP/IP předpokládá existenci následujících čtyř vrstev:
|
Součástí této představy je například zásada, že zajištění spolehlivosti je úkolem koncových účastníků, a nikoli meziuzlů, přes které data pouze prochází (jako je tomu u referenčního modelu ISO/OSI). Filosofie TCP/IP proto předpokládá, že na nižších vrstvách budou poskytovány pouze nespolehlivé přenosové služby nespojovaného charakteru, které ale zato mohou být velmi efektivní (především rychlé). Zajištění spolehlivosti je pak ponecháno na vyšších vrstvách, a to ještě jen pro potřeby takových aplikací, které spolehlivost vyžadují, ale nechtějí si ji zajišťovat samy.
TCP/IP má méně vrstev než referenční model ISO/OSI (jen čtyři), a také jeho přístup k "bohatosti" služeb je spíše opačný: začíná s jistým minimem, ke kterému se teprve postupně přidávají nejrůznější další rozšíření. Na rozdíl od referenčního modelu, který se teprve prosazuje, si TCP/IP získalo své místo ve světě počítačových sítí v podstatě ještě dříve, než se stalo standardem.
Vztah MS DOSu a Unixu k sítím
Pro naše povídání o interoperabilitě na příkladu spolupráce MS DOSu a Unixu je velmi podstatné, jaký je vztah obou těchto operačních systémů k jednotlivým síťovým architekturám.
Relativně jednoduchá je situace u Unixu. Přes veškerou roztříštěnost Unixovské komunity zde panuje jednoznačná shoda o tom, že Unix má používat protokoly TCP/IP. Tyto protokoly sice vznikly zcela nezávisle na Unixu (v rámci sítě ARPANET, na objednávku grantové agentury DARPA amerického ministerstva obrany), ale poměrně brzy byly implementovány i v prostředí Unixu (opět za peníze agentury DARPA), a dnes jsou obvykle standardní součástí dodávky tohoto operačního systému. To samozřejmě nevylučuje, aby Unix jako operační systém používal jiné přenosové protokoly než protokoly TCP/IP (což činí například UnixWare firmy Novell, který standardně používá protokoly IPX/SPX), ale v současné době protokoly TCP/IP v prostředí Unixu zcela dominují.
V prostředí MS DOSu je tomu jinak. MS DOS nemá žádnou standardně zabudovanou podporu sítí. Jedinou výjimkou je tzv. NetBIOS neboli síťová varianta BIOS-u, která nabízí základní přenosové služby, ale koncepčně se spíše vymyká všem vrstvovým modelům. Více než svým kvalitám vděčí za svou stávající existenci renomé firmy IBM, která jej vytvořila pro svou vlastní lokální síť PC Network. V dnešní době má NetBIOS význam především jako společný jmenovatel různých jiných síťových architektur, jejichž implementace chování NetBIOSu emulují. Jedním z koncepčních nedostatků NetBIOSu je například to, že všechno považuje za jedinou síť, resp. že nerozeznává více jednotlivých sítí. V důsledku toho pak protokoly NetBIOSu nelze tzv. směrovat (tj. přepojovat mezi jednotlivými sítěmi), což způsobuje nemalé komplikace při dnes tak častém vzájemném propojování dílčích sítí.
Počítače PC s MS DOSem proto používají většinou jiné síťové protokoly než NetBIOS, které jsou jim různým způsobem dodatečně "implantovány" (nejčastěji formou rezidentních programů). Například v sítích Novell NetWare jde o protokoly IPX/SPX, které je schopna používat i celá řada dalších síťových nadstaveb. I v prostředí počítačů PC však získávají stále větší popularitu také protokoly TCP/IP, a díky tomu je pak jejich interoperabilita s Unixovskými počítači jednodušší. Ale o tom, jak MS DOSu vnutit protokoly TCP/IP, si povíme zase až příště.