


Jména v TCP/IP sítích - II.
V minulém dílu jsme se zabývali otázkou symbolických jmen počítačů a bran v TCP/IP sítích a dospěli jsme k tomu, jakým způsobem se přidělují doménová jména v Internetu. Nyní se budeme věnovat otázce, jak na základě symbolických jmen získávat odpovídající IP adresy.Připomeňme si ještě jednou, že otázku doménových jmen v TCP/IP sítích řeší standard DNS (Domain Name System), který má dvě základní části: první z nich určuje syntaxi doménových jmen a pravidla pro delegování pravomoci a odpovědnosti za jejich přidělování, zatímco druhá část se týká implementace mechanismu pro převod doménových jmen na jim odpovídající IP adresy.
 |
 |
Jak je tomu ve skutečnosti
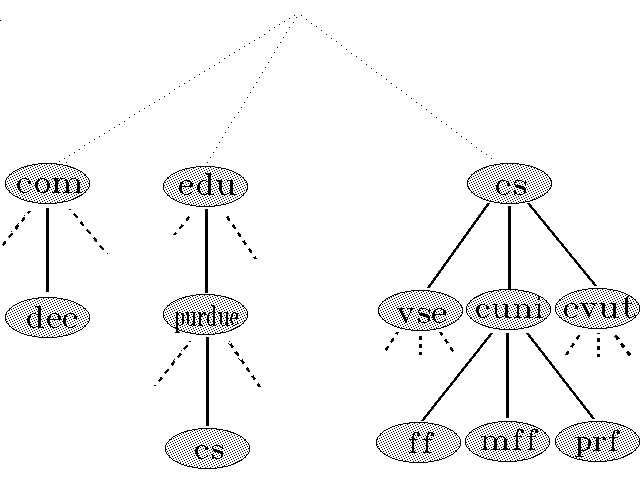
Právě naznačený příklad je samozřejmě dosti zjednodušený, ale jinak dobře vystihuje celkovou filosofii převodu symbolických doménových jmen na IP adresy.
Prvním praktický problém vyvstává hned v okamžiku, kdy je třeba se obrátit na server jmen domény nejvyšší úrovně - každý potenciální tazatel by totiž musel znát adresy serverů jmen všech domén nejvyšší úrovně. Proto se všem těmto serverům nejvyšší úrovně nadřazuje ještě jeden, tzv. kořenový server (root server), a pouze tento kořenový server musí být znám všem potenciálním žadatelům o převod doménových adres. V praxi je tento kořenový server několikanásobně zálohován.
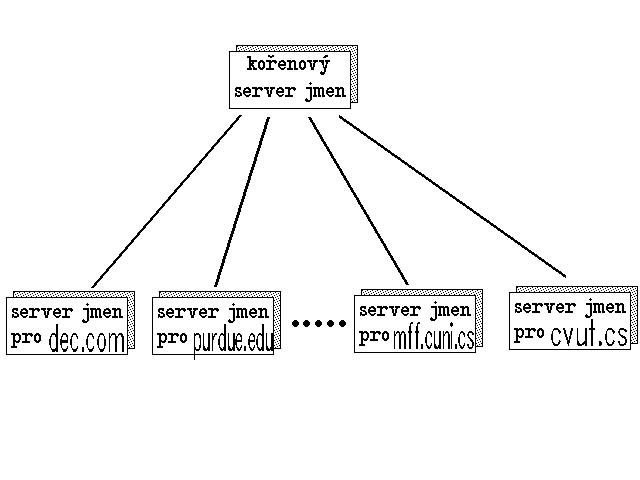 |
Rekurzivní a iterativní převod
Iniciátorem převodu doménového jména na IP adresu (anglicky: name resolution) je vždy programová entita hostitelského počítače (tzv. name resolver), která vůči celé soustavě serverů jmen vystupuje jako klient. Se svým požadavkem na převod doménového jména se tato entita obrací na některý ze serverů, který může postupovat dvojím způsobem: pokud není schopen převod zajistit, sám se obrátí na jiný server jmen, který převod zajistí, výsledek vrátí prvním serveru, a ten jej pak vrátí původnímu žadateli. Pak jde o tzv. rekurzivní převod (recursive resolution). Alternativou je tzv. iterativní převod (iterative resolution), při kterém dotázaný server jmen buď provede převod sám, nebo pouze vrátí adresu jiného serveru jmen, na který se pak musí žadatel o převod znovu obrátit sám.
Zajímavou otázkou je to, kam se má žadatel o převod obrátit nejprve - zda má začít shora, a obrátit se na kořenový server, nebo má naopak postupovat naopak odspodu, a obrátit se nejprve na "místní" server jmen? Ve prospěch druhé možnosti hovoří hned několik skutečností: kdyby se všichni obraceli přímo na kořenový server, tento by byl brzy zahlcen. Navíc požadavky na převod doménových jmen se nejčastěji týkají právě "místních" jmen, které dokáže převést místní server. Ten je kromě toho schopen fungovat i v případě eventuálního výpadku vyšších vrstev celého stromu name serverů (i když to je vzhledem k jejich zálohování nepříliš pravděpodobné).
Použití vyrovnávacích pamětí (caching)
Kdyby se každý hostitelský počítač musel obracet na soustavu serverů jmen pokaždé, kdy potřebuje převést některé doménové jméno na jemu odpovídající IP adresu, byla by to pro celou síť neúnosně velká zátěž. Pro zefektivnění celého mechanismu převodu se proto počítá s tím, že hostitelské počítače si po určitou dobu pamatují výsledky dříve uskutečněných převodů. Každý hostitelský počítač si proto bude udržovat ve vhodné vyrovnávací paměti (paměti cache) databázi symbolických jmen a jim odpovídajících IP adres. Aby tuto svou databázi udržel v konzistentním stavu, odpovídajícím skutečnosti, bude každá položka této databáze "zastarávat" - po určité době ztratí svou platnost, a příslušný převod bude muset být v okamžiku potřeby vyvolán znovu.
Podobně postupují i servery jmen. Kromě doménových jmen, které jsou schopny (přesněji: oprávněny) převádět samy, se při rekurzivních převodech dozvídají i odpovídající IP adresy k jiným doménovým jménům. Také ty si udržují ve své vyrovnávací paměti, a v případě žádosti o převod je mohou poskytnout - ovšem s poznámkou, že nejsou k jejich převodu kompetentní (tj. že jde o tzv. neautoritativní (nonauthoritative) převod). Současně s tím poskytnou žadateli o převod i odkaz na ten server jmen, který je k převodu kompetentní. Iniciátor převodu pak naloží s touto informací podle vlastního uvážení. Jde-li mu o rychlost, použije tento neautoritativní převod, jde-li mu naopak o spolehlivost, obrátí se na příslušný server jmen, který je pro daný převod kompetentní.
Ještě většího zefektivnění celého mechanismu převodu doménových jmen na IP adresy lze pak dosáhnout tím, že jednotlivé hostitelské počítače si v okamžiku svého spuštění vyžádají od místního serveru jmen celou jeho databázi doménových jmen a jim odpovídajících IP adres. Z té pak vychází, a na server jmen se obrací jen při její aktualizaci (po "zastarání" některé položky) či pro její doplnění o nové doménové jméno, jehož odpovídající IP adresa ještě v databázi není.